Are AI costs eating
your product margins?
Cut LLM costs by 80% with custom SLMs
Why teams switch to custom SLMs
Lower costs, same accuracy
Custom SLM tuned to your task matches frontier accuracy from a 100x smaller model, which means 80% lower cost-per-request.
Train and integrate in 1 day
Building an SLM requires 10 minutes of human effort; it deploys behind an OpenAI-compatible endpoint, so integration is changing your URL.
Take control of your model
A custom SLM puts you in control of your inference cost, rate limits, and roadmap. The model is yours to run where you need it.
30M+ people use distil labs models today







How it works
- 1
Route 1% of your traffic
Point 1% of production traffic at your distil labs endpoint. It forwards each request to your LLM so responses are unchanged, and captures the traces used to create synthetic data for SLM training.
client = OpenAI( - base_url="https://api.openai.com/v1", + base_url="https://ead9fb75.i.distillabs.ai/v1", api_key="your-distil-api-key", ) - 2
Build and deploy your SLM
From traces to a deployed SLM in four commands. Behind each one, distil labs handles ML, so you can deploy with confidence.
$ distil traces from ead9fb75 ✓ Traces trc_5f21 captured from endpoint ead9fb75 $ distil synthetic-data from trc_5f21 ✓ Synthetic data synth_a4f9 created from traces trc_5f21 $ distil slm from synth_a4f9 ✓ Training slm_b46f created from synthetic data synth_a4f9 $ distil endpoint ead9fb75 deploy slm_b46f ✓ Endpoint ead9fb75 now served by slm_b46fdistil labs6 stagesCreate synthetic data↻ per batch1Generate batch of datacreate synthetic examples for your task2Validate batch of datafilter, dedupe, drop low-quality samples3Match distribution to targetfocus generation on underrepresented sections4Post-training (SFT + RL)fine-tune, then reinforce5Model quantizationcompress weights, hold accuracy6Optimized deploymentcompile & serve at low latency - 3
Send 100% of your traffic
Send all traffic to the same endpoint. It now serves your SLM at a fraction of the cost.
80% lower cost per request
How it works
Step 1 of 3
Route 1% of your traffic
Point 1% of production traffic at your distil labs endpoint. It forwards each request to your LLM so responses are unchanged, and captures the traces used to create synthetic data for SLM training.
client = OpenAI(
- base_url="https://api.openai.com/v1",
+ base_url="https://ead9fb75.i.distillabs.ai/v1",
api_key="your-distil-api-key",
)Step 2 of 3
Build and deploy your SLM
From traces to a deployed SLM in four commands. Behind each one, distil labs handles ML, so you can deploy with confidence.
$ distil traces from ead9fb75
✓ Traces trc_5f21 captured from endpoint ead9fb75
$ distil synthetic-data from trc_5f21
✓ Synthetic data synth_a4f9 created from traces trc_5f21
$ distil slm from synth_a4f9
✓ Training slm_b46f created from synthetic data synth_a4f9
$ distil endpoint ead9fb75 deploy slm_b46f
✓ Endpoint ead9fb75 now served by slm_b46fStep 3 of 3
Send 100% of your traffic
Send all traffic to the same endpoint. It now serves your SLM at a fraction of the cost.
80% lower cost per request
From our blog

How Knowunity used distil labs to cut their LLM bill by 68%
Knowunity, an edtech startup processing hundreds of millions of AI requests monthly, used distil labs to train a custom small language model that cut inference costs by 68% while improving classification accuracy from 81% to 93%.
Read more →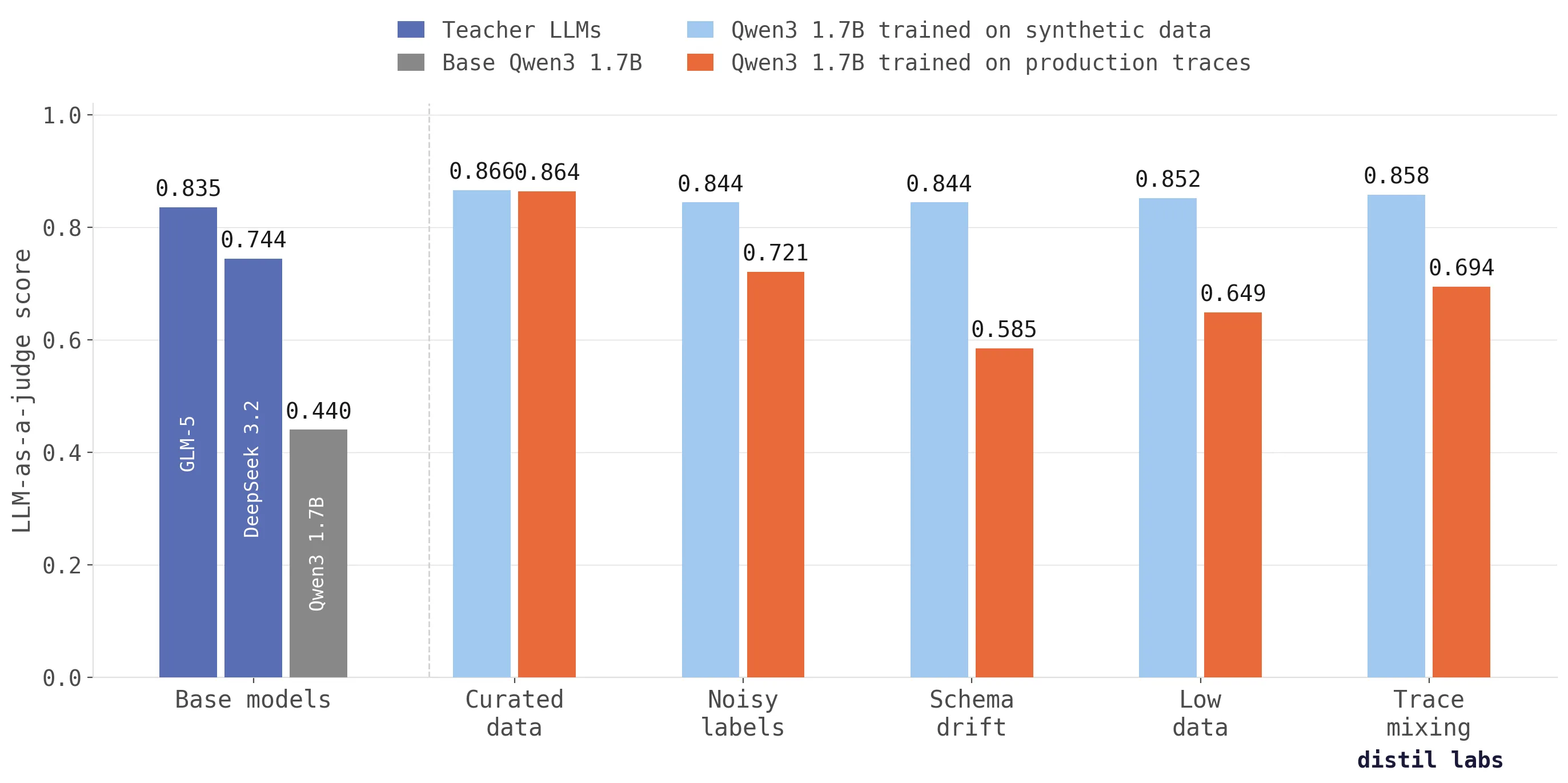
Why training on production traces fails (and what to do instead)
Training directly on production traces doesn't work as well as you'd expect. We tested across five scenarios and synthetic data from traces scores up to 26 percentage points higher in accuracy.
Read more →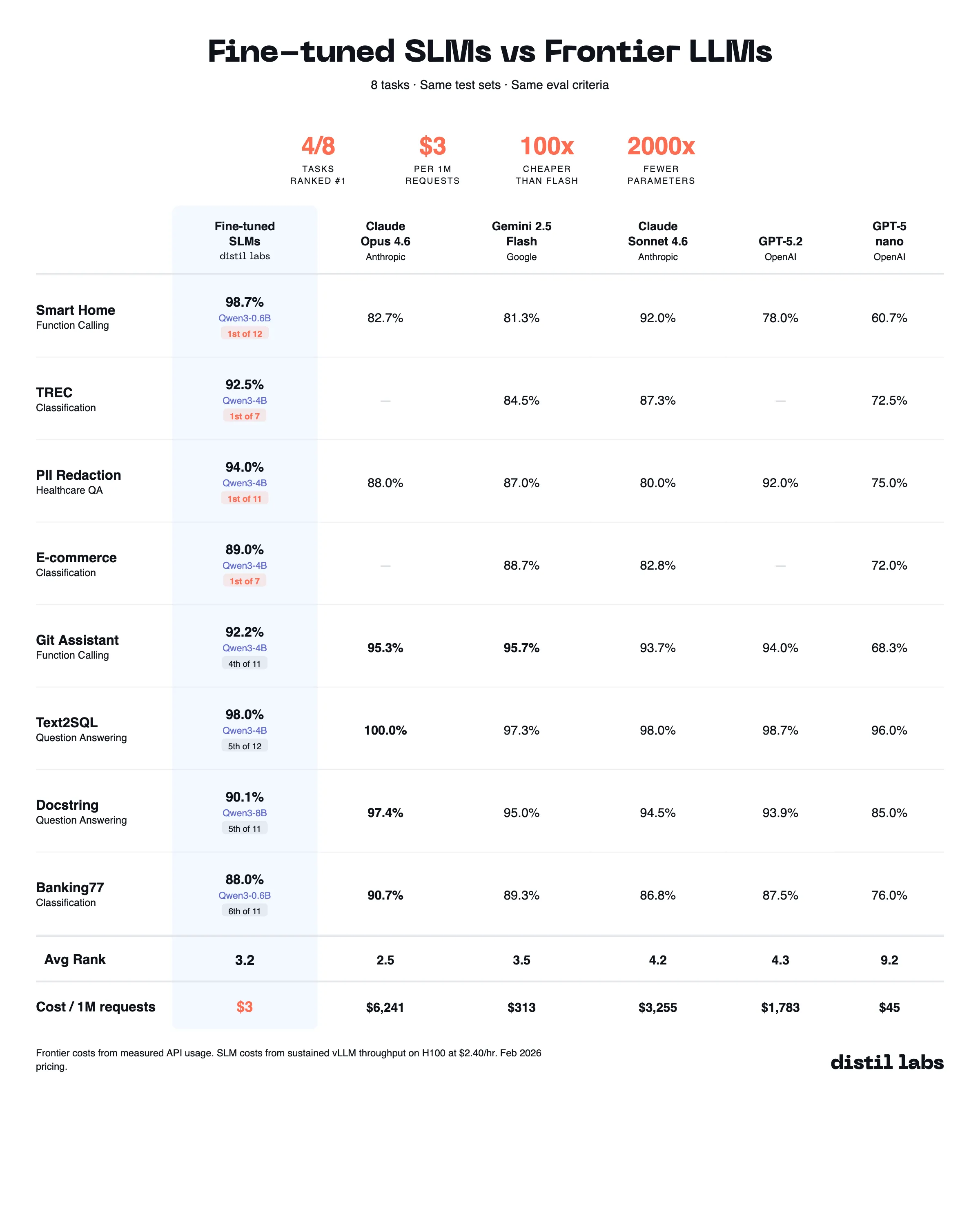
The 10x Inference Tax You Don't Have to Pay
Benchmarking fine-tuned small language models (0.6B-8B) against 10 frontier LLMs across 8 datasets shows that task-specific SLMs match or beat frontier models at 10-100x lower inference cost.
Read more →What Our Customers Say
We needed a small model that could power our product on an IBM P11, entirely on-premises. distil labs’ fine-tuned models allowed us to ship a self-contained solution where the SLM and our graph platform coexist on the same hardware. For customers in regulated industries, this means AI-powered query generation with complete data privacy – nothing ever leaves their environment.
David J. Haglin
Co-Founder and CTO at Rocketgraph
Using distil labs, we were able to spin up highly accurate custom small models tailored to our workflows in no time. Those models cut our inference costs by roughly 50% without sacrificing quality. The distil labs team was incredibly supportive as we got started and helped us get to production smoothly.
Lucas Hild
Co-Founder & CTO at Knowunity
The distil labs platform accelerated the release of our cybersecurity-specialized language model, KINDI, enabling faster iterations with greater confidence. As a result, we ship InovaGuard improvements sooner and continuously boost investigation accuracy with every release.
Samir Bennacer
Co-Founder and CTO at Octodet
The Team








Backed by






Your first model is free to train
Bring 20 examples or a day of traces. Leave with a model and its eval report.