You’re building a customer-support assistant. A frontier LLM handles every conversation well, but you’re paying frontier prices for “look up my reservation” and “what’s my baggage allowance,” which are the overwhelming majority of turns. The hard turns (refund eligibility under fare rules, compensation math across passengers, multi-constraint rebooking) are a small minority, but they’re the ones where a small model quietly gets it wrong. Pick either model alone and you either bleed money on trivial turns or risk silent errors on the turns that matter most.
A two-tier cascade gets the best of both. The fine-tuned SLM resolves the easy majority at a fraction of the cost, and the frontier model handles the hard minority where it actually earns its price. Each model does only what it’s good at, so the pair matches the large model’s quality at a fraction of its cost, without the silent errors you’d get from the small model alone. 2 + 2 > 4.
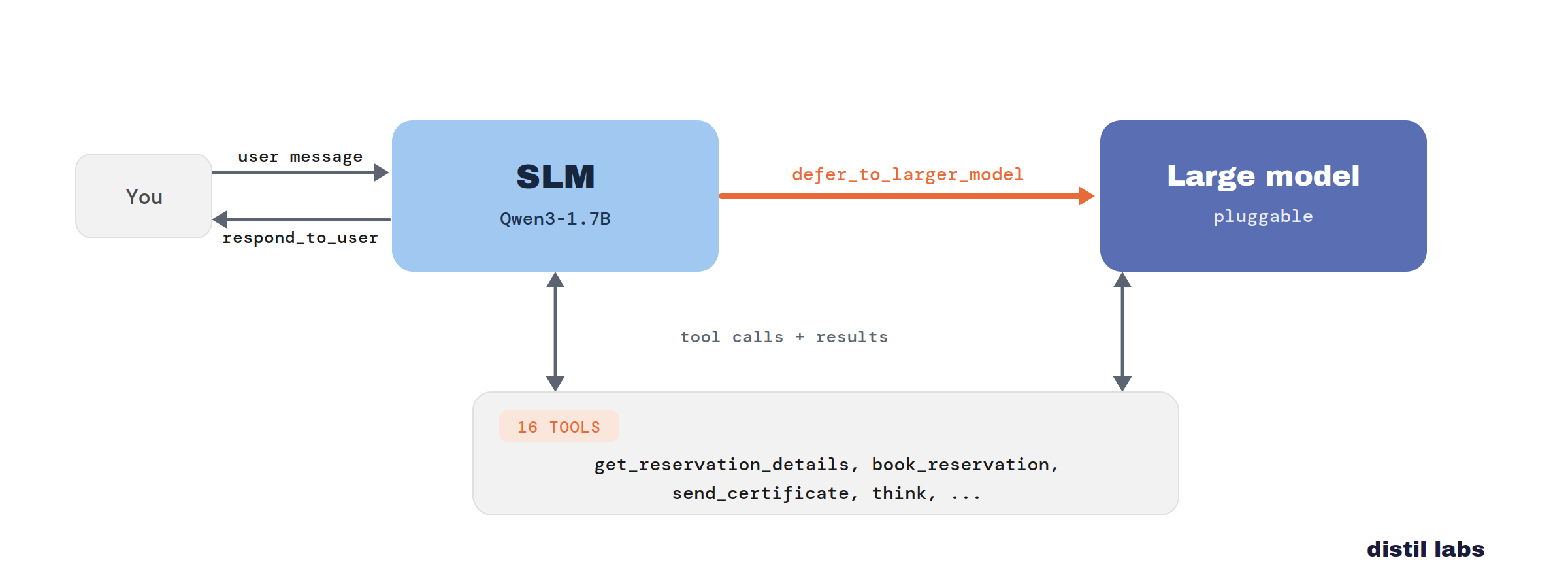
What makes this practical is that there is no elaborate routing system to build. No separate classifier, no confidence thresholds to tune, no second model deciding who handles what. The SLM is trained to recognize when it’s out of its depth and emit a single defer_to_larger_model tool call, and the orchestrator just honors it.
We back this up with a working demo: a flexible airline customer-support bot where a fine-tuned Qwen3-1.7B handles the bulk of turns and escalates the hard ones to a larger model. If you have a support workflow in mind, get in touch and we’ll show you what a deferral SLM can do for your domain.
Two Bad Options
Run every turn on a frontier model and you get the accuracy, but you pay frontier prices for traffic that is mostly trivial lookups. Run every turn on a small fine-tuned model and the economics flip in your favor, but the hard tail is exactly where a small model returns a confident, wrong answer. The gap between the two is wide. For a typical support turn (policy plus tool schemas plus dialogue history plus the user message, roughly 800 input and 100 output tokens):
| Approach | Cost / 1M turns | Latency / turn |
|---|---|---|
| Frontier model, every turn | ~$3,000 | 500-1,200 ms |
| Small model (cloud), every turn | ~$600 | 100-300 ms |
Frontier cost from GPT-4o list pricing of $2.50 / $10 per 1M input/output tokens, applied to the per-turn payload above. The small model runs at roughly a fifth of that on small-model token rates, and latency reflects each model served behind a network call.
On paper you have to choose: pay for accuracy you don’t need on every turn, or save money and accept that the hard turns will sometimes come back wrong. Most teams pick one and live with the downside.
The Best of Both Worlds
You don’t have to choose. A two-tier cascade sends the easy majority of turns to the small model, which answers at roughly a fifth of the cost and a few hundred milliseconds, and routes only the genuinely-hard minority to the frontier model, where the accuracy is worth its price. You get the frontier model’s answer on the turns that need it and the small model’s economics and speed on the turns that don’t, in one system.
Because the frontier model is billed only on the deferred minority, the blended cost stays far below running everything on the frontier, while conversation quality holds because the hard turns are exactly the ones that get escalated. In our demo the small model handles ~96% of turns and escalates only the hardest ~4%, so the blended bill is dominated by the cheap tier (≈$700 per 1M turns at the per-turn rates above, against ~$3,000 for all-frontier) while quality stays statistically indistinguishable from running everything on the frontier model (see the Results below). Cheaper than all-frontier, more reliable than all-small. 2 + 2 > 4.
The obvious worry is that a cascade adds moving parts: another model to route traffic, thresholds to tune, a system to keep in sync. It doesn’t. The routing decision lives inside the small model itself.
No Router. The Model Just Knows When to Defer.
The usual way to add a cascade is to bolt on a router: a difficulty classifier, a confidence threshold off the model’s logprobs, or a second model deciding who handles what. That is all extra infrastructure to tune and keep in sync with your policy, and confidence heuristics are badly calibrated to begin with.
We skip it. The deferral is trained into the small model: during distillation the teacher marks the genuinely-hard turns and the student learns to recognize them. At runtime the SLM emits a single defer_to_larger_model tool call, exactly like any other tool, and the orchestrator hands off the rest of the conversation. The decision uses the model’s full view of the conversation rather than a score bolted on top, which makes it both simpler to run and better calibrated.
Results
We evaluate on held-out airline support turns scored by an independent GLM-5 judge (the score is the fraction of responses rated correct). The comparison is matched per-turn — same turns, same judge pass — putting the full cascade (the SLM handles most turns and escalates the hardest ~4% to the frontier model) head to head against the frontier model handling every turn, under both a strict and a relaxed judge rubric.
| System | Quality (strict judge) | Quality (relaxed judge) | Frontier-model calls |
|---|---|---|---|
| Frontier model only (GLM-5) | 0.79 ± 0.03 | 0.88 ± 0.03 | 100% |
| Full cascade (SLM + escalation) | 0.76 ± 0.03 | 0.85 ± 0.03 | ~4% |
The two are within noise. The quality gap is +0.03 ± 0.03 (strict) and +0.03 ± 0.02 (relaxed); the 95% confidence interval of the difference includes zero, and a paired McNemar test finds it not statistically significant under either rubric. The cascade is statistically indistinguishable from the all-frontier system in quality while making ~25x fewer frontier-model calls — roughly 96% of turns are handled by the much cheaper 1.7B.
Fine-tuning is what makes this possible: the same untrained Qwen3-1.7B scores just 0.42 on this set and never defers at all (0% escalation). Knowing when to escalate is a learned skill, not something you get for free from a capable base model. (Scores are reference-free LLM-as-a-judge ratings, not exact-match, and carry ~±0.03 run-to-run noise, so differences this small are not meaningful.)
See It Working
Everything above is backed by a working system you can clone and run. The flexible customer-support bot wires up the two-tier cascade end to end on an airline support task.
You ── user message ──▶ ┌──────────────┐ defer_to_larger_model ┌──────────────┐
│ SLM │ ────────────────────────▶ │ Large model │
respond_to_user ◀──── │ Qwen3-1.7B │ (sticky: rest of conv) │ (pluggable) │
└──────┬───────┘ └──────┬───────┘
│ tool calls + results ◀─────────────────┘
▼
get_reservation_details, book_reservation,
send_certificate, think, ... (16 tools)Every assistant action is a single tool call, including talking to the customer via respond_to_user. That keeps the orchestrator thin: it calls the active model, gets back one tool call, executes it, and feeds the result back. On a hard turn the SLM calls defer_to_larger_model, and from that point the larger model handles the rest of the conversation with the same tools and the same policy. Both are loaded from job_description.json, the same artifact the model is trained on, so the demo and the model never drift apart.
The SLM resolves ordinary turns itself:
You: Hi! Can you pull up my reservation, the ID is 8JX2WO?
· [SLM] get_reservation_details(reservation_id="8JX2WO")
Bot: [SLM] Here are the details of your reservation 8JX2WO. Anything else I can help with?And on a hard eligibility turn, it defers, and the larger model takes over with a policy-grounded answer:
You: I want a full refund. It's a basic economy ticket and I've already flown the first leg. Am I eligible?
⤴ SLM deferred to the large model.
reason: refund eligibility depends on fare class (basic economy) + partially-flown segments
→ the large model now handles the rest of this conversation.
Bot: [LARGE] You are not eligible for a full refund because you have already flown the first leg
of your basic economy ticket. Let me connect you with a human agent for next steps.Each turn is badged [SLM] or [LARGE] and tool calls are traced inline, so you can see exactly where the conversation is handled. Tool execution sits behind a single integration point, execute_tool in tools.py: point it at your reservation backend (or the tau-bench airline environment) and the orchestrator and model stay unchanged.
Weights available, deploy anywhere. The distilled Qwen3-1.7B ships in the demo repo as both GGUF (for llama.cpp) and safetensors (for vLLM /
AutoModel), so the cascade and the results above reproduce end to end. The demo serves the SLM on your own machine so you can clone and run it in one command, but the cascade doesn’t depend on that: host the 1.7B on your own GPU or behind a small-model API and the economics are the same. The savings come from the SLM being cheaper to serve than a frontier model, not from where it runs.
How We Built It
The model is distilled from traces, production-style support conversations, using the Distil Labs training-from-traces pipeline. It is mostly data work, then one training run:
- Traces, one task. Start from a public multi-turn tool-calling dataset (Salesforce APIGen-MT), filtered to the airline domain (1,587 seed conversations) so every conversation shares one policy and one tool set. Wrap each assistant reply in a single
respond_to_usercall so every turn is exactly one tool call: that uniform contract is what keeps the cascade clean. - Deferral as data. Add one tool,
defer_to_larger_model(reason), plus a short guideline that defines “hard” by the structure of the problem (non-obvious eligibility, several interacting rules, multi-step math, ambiguous judgement), not by asking the model to guess its own limits. - Teacher cleans and relabels. A strong teacher (GLM-5) rewrites each trace into a clean, policy-correct conversation and marks the genuinely-hard turns with
defer_to_larger_model, a few percent of the total. Real traces are messy, so the pipeline is built to absorb truncated logs, corrupted arguments, and renamed tools: point it straight at your own. - Distill. The pipeline expands the seed traces into several thousand synthetic examples that preserve the deferral behavior, then fine-tunes Qwen3-1.7B on them.
Distil Labs is a platform for training task-specific small language models via knowledge distillation: models 50-400x smaller than current state-of-the-art LLMs that maintain comparable accuracy on a bounded task while being far cheaper and faster to run. Check out our docs to dive deeper.
Beyond Cost
Cost is the most visible win, but a small model is also much faster per turn (the latency column above), which tightens every interaction and matters even more for voice support, where the same cascade applies and the small tier keeps responses snappy (see our voice-assistant post). And because deferral is an explicit, inspectable tool call, you decide exactly which turns are worth a frontier model instead of sending all of them there by default.
Train Your Own Deferral SLM
The workflow is generic across support domains. Provide a task description and a handful of example traces, and the platform handles synthetic data generation, fine-tuning, and evaluation.
curl -fsSL https://cli-assets.distillabs.ai/install.sh | sh
distil login
distil model create my-support-deferral
distil model upload-traces <model-id> --data ./data # traces + job_description + config
distil model run-training <model-id>
distil model download <model-id>You can also drive training from Claude Code with the Distil CLI skill. For choosing the right base model for your task, see our benchmarking study.
If your support assistant runs entirely on a frontier model today, you’re paying frontier prices and frontier latency for traffic a much smaller, cheaper model could serve. A cascade with a trained deferral SLM gives you frontier-level quality overall — the frontier model on the hard minority, the small model’s economics and speed on everything else — with no router to build. If you have a support workflow in mind, get in touch and we’ll show you what a deferral SLM can do for your specific use case.
distil labs trains task-specific small language models that are cheaper and faster per request than general-purpose LLMs, with equal-or-better accuracy on bounded tasks. Docs · GitHub · Slack