Blog & Demos
Tutorials, case studies, benchmarks, and open-source demos — everything you need to build with small language models.
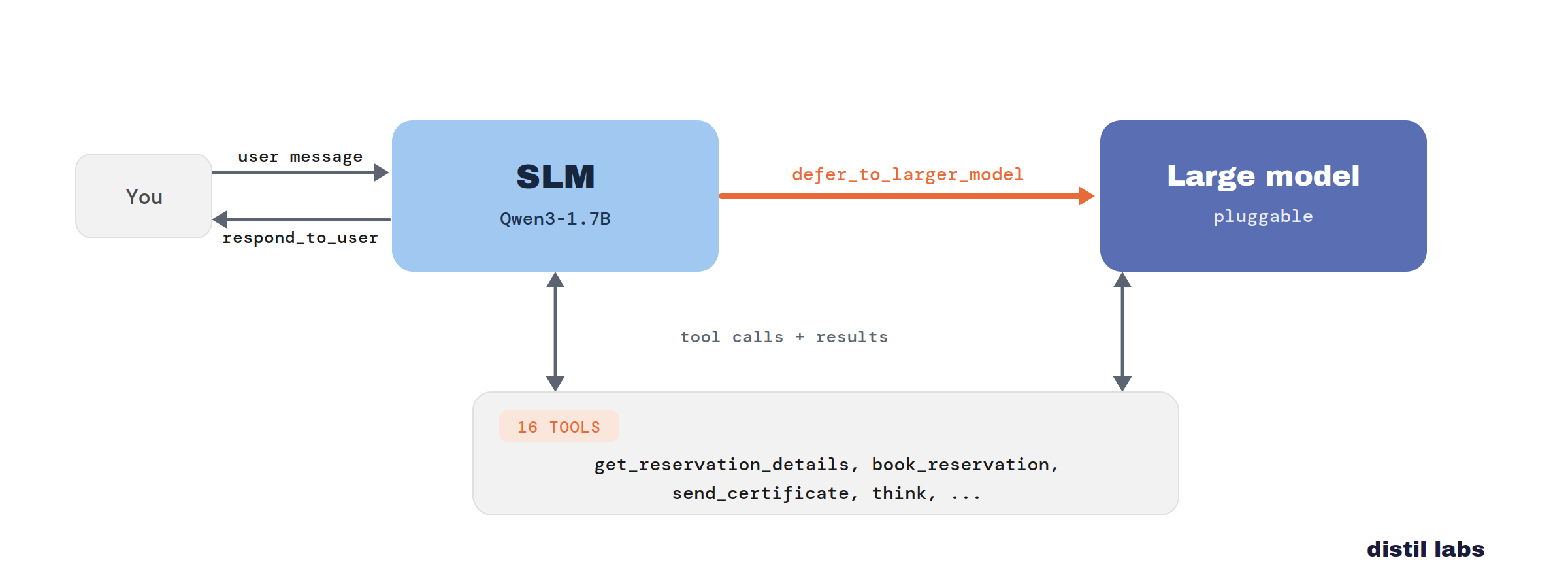
Don't Build a Router. Train the Small Model to Know When to Defer.
A fine-tuned small model handles the easy majority of customer-support turns and defers the genuinely-hard minority to a frontier model — matching all-frontier quality at a fraction of the cost. No router, no thresholds, no second classifier: the small model is trained to recognize when it's out of its depth and escalate with a single tool call.

Giving Superpowers to Your LLMs with SLMs
Part 2 of the autonomous bug-fixing agent series: why the intelligent harness keeps the LLM orchestrator general-purpose and offloads domain work to cheap, fine-tuned SLM tools — cutting cost from ~$0.07 to ~$0.001 per incident.

Distil PII Redactor: an OpenClaw Skill
Locally redact PII from text using a fine-tuned 1B parameter model packaged as an OpenClaw skill. Your sensitive data never leaves your machine.

Autonomous Bug Fixing Agent with distil labs' SLM and Warp Oz
A self-healing loop that diagnoses production failures with a fine-tuned 0.6B SLM and applies the fix with Warp Oz — closing incidents in seconds, no humans paged.

Train an SLM from your production traces with the distil labs Claude skill
A walkthrough of using the distil labs Claude skill to turn 327 noisy production traces into a fine-tuned Qwen3-1.7B multi-turn tool-calling model, deployed on a managed endpoint in a single conversation.
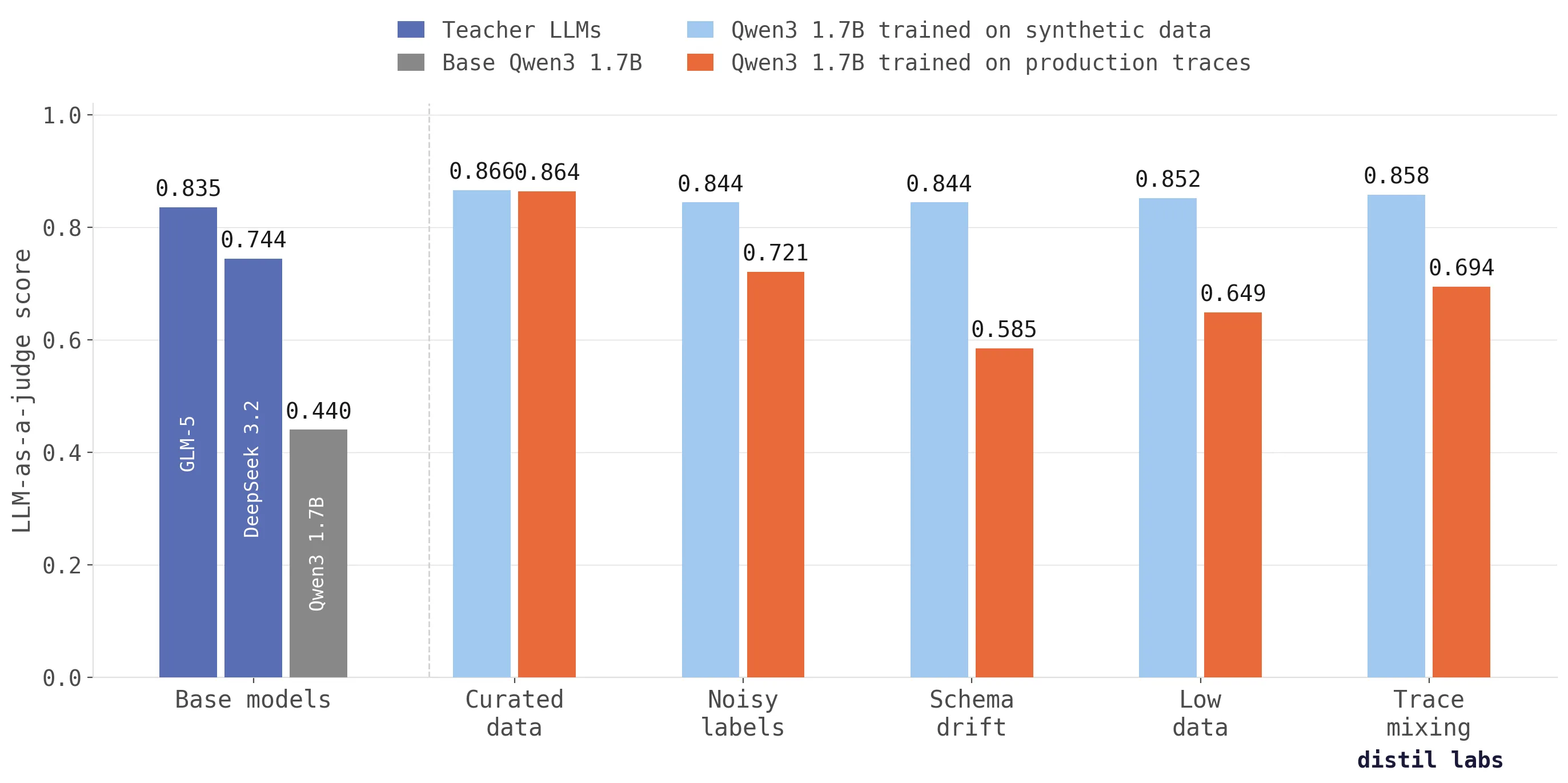
Why training on production traces fails (and what to do instead)
Training directly on production traces doesn't work as well as you'd expect. We tested across five scenarios and synthetic data from traces scores up to 26 percentage points higher in accuracy.
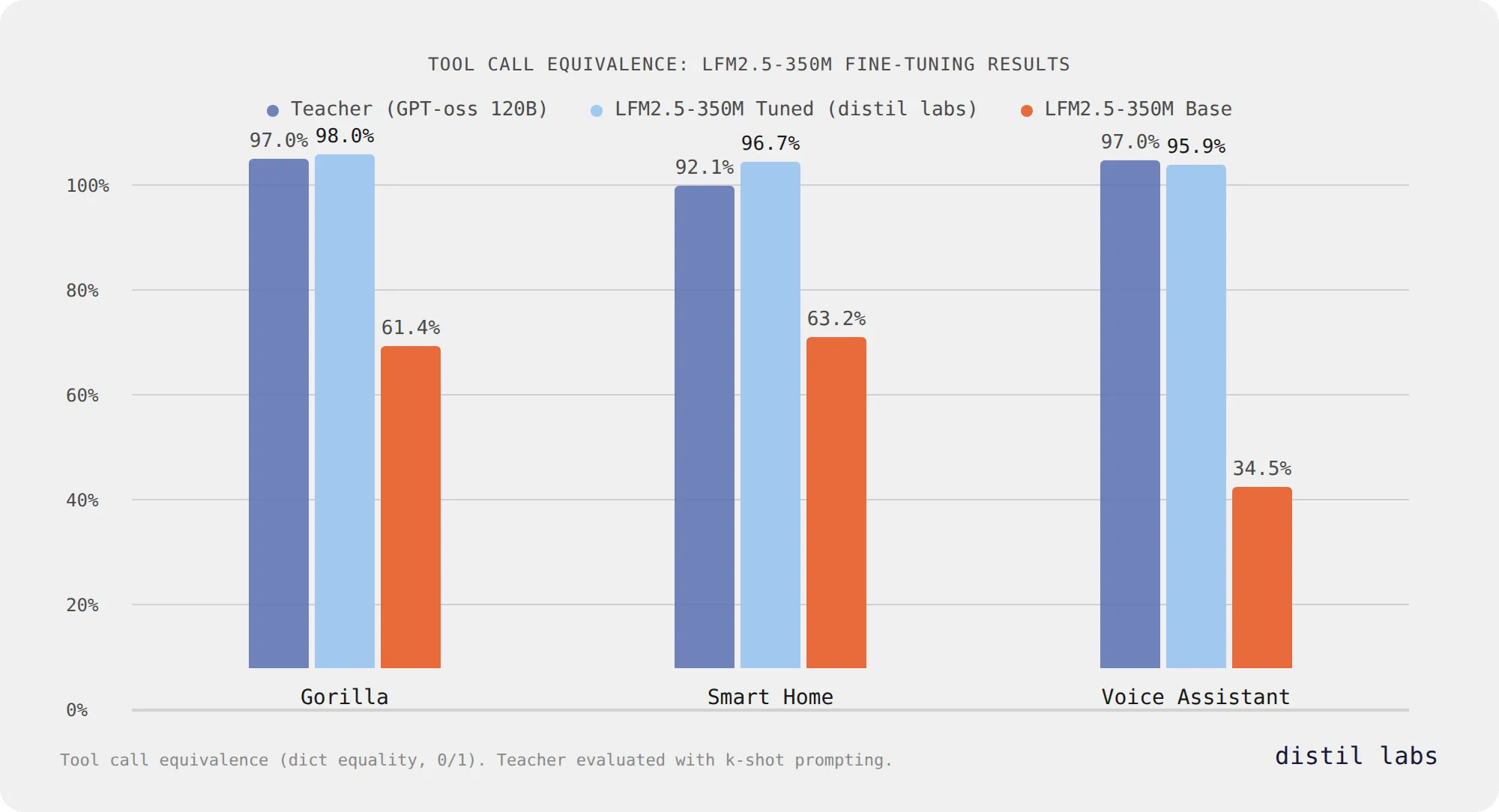
Fine-Tuning Liquid's LFM2.5: Accurate Tool Calling at 350M Parameters
Liquid AI's LFM2.5-350M reaches 96-98% tool call equivalence after fine-tuning with distil labs across three benchmarks, matching or exceeding a 120B teacher model while staying at 350M parameters.
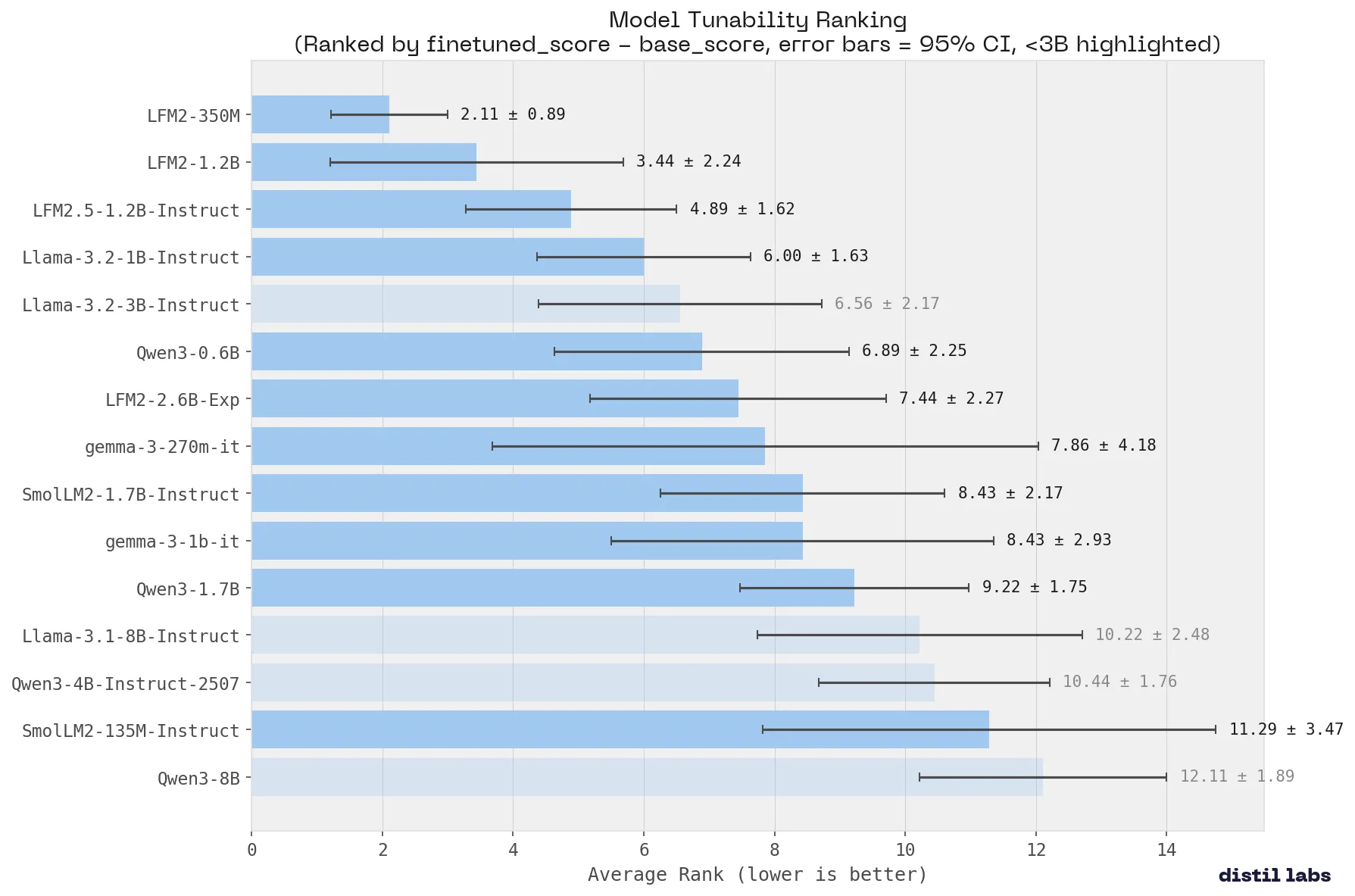
What Small Language Model Is Best for Fine-Tuning
We benchmarked 15 small language models across 9 tasks to find the best base model for fine-tuning. Qwen3-8B ranks #1 overall. Liquid AI's LFM2 family is the most tunable. Fine-tuned Qwen3-4B matches a 120B+ teacher on 8 of 9 benchmarks.
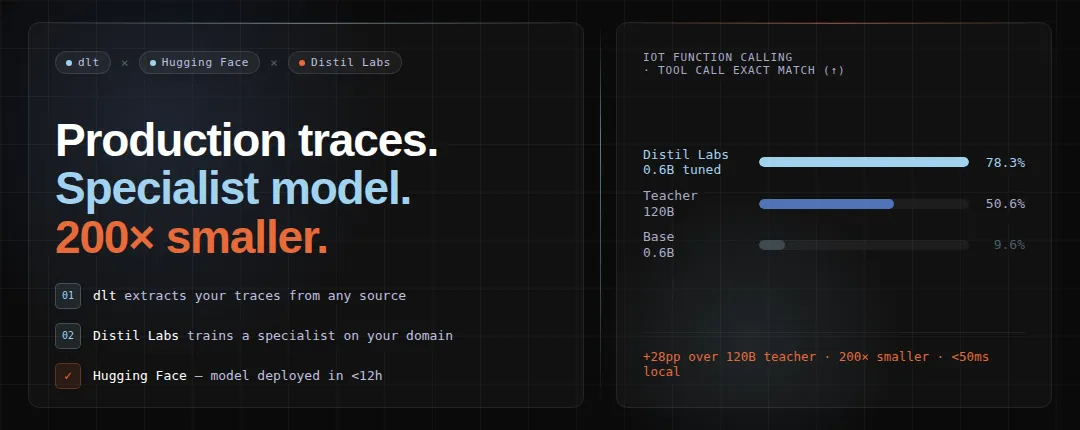
A 0.6B model outperformed a 120B LLM by 29 points - using dlt, distil labs, and Hugging Face
How to turn production LLM traces into a deployed specialist model using dlt for trace extraction and distil labs for training, achieving 79% exact match with a 0.6B model that beats a 120B teacher by 29 points.