TL;DR
- Liquid AI’s LFM2.5-350M is built for structured outputs, data extraction, and tool calling, but like most small models, it needs task-specific fine-tuning to hit production-grade accuracy on multi-turn tool calling.
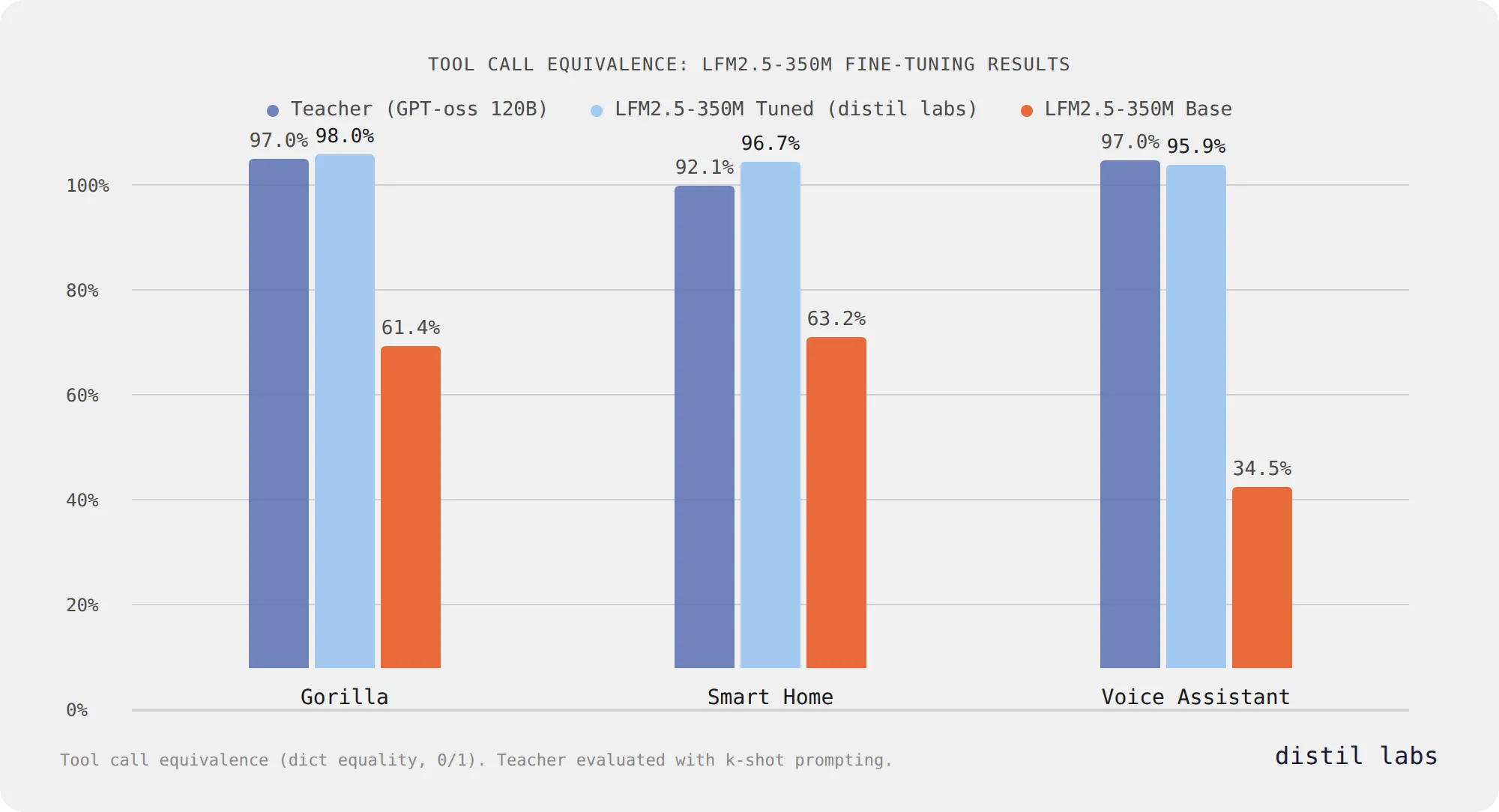
- After fine-tuning with distil labs, it reaches 96-98% tool call equivalence across three benchmarks, matching or exceeding a 120B teacher model while staying at 350M parameters.
- Three tasks, same story: shell command execution (61.4% → 98.0%), smart home control (63.2% → 96.7%), and banking voice assistant (34.5% → 95.9%).
- LFM2.5’s novel hybrid architecture makes it faster and more memory-efficient than transformer-based models of similar size, perfectly suited for edge deployment on CPUs, NPUs, and GPUs.
- If you have a function calling task, start training your own model with a prompt and a few examples.
LFM2.5: A New Kind of Small Model
We’ve partnered with Liquid AI to showcase what happens when their efficient hybrid architecture meets task-specific fine-tuning on the distil labs platform. The results speak for themselves.
Liquid AI’s LFM2.5 family is not your typical transformer. Built on a hybrid architecture of multiplicative gates, short convolutions, and grouped query attention, LFM2.5 is designed from the ground up for edge deployment. A recent deep dive into on-device AI explains why this matters: standard transformers hit a memory wall on edge devices because their KV cache grows with every token, while LFM2’s architecture cuts that cache by up to 90% by replacing most attention layers with zero-cache convolution blocks.
The tradeoff for all that speed and efficiency is out-of-the-box accuracy. A 350M model simply cannot store as much knowledge or handle as many task patterns as a multi-billion parameter LLM. Liquid AI is upfront about this:
We recommend fine-tuning LFM2.5 for your specific use case to achieve the best results.
That’s exactly what we did. Using the distil labs platform, we fine-tuned LFM2.5-350M on three multi-turn tool calling tasks and pushed accuracy from 34-63% to 96-98%, matching or exceeding a model 343× its size.
Why Fine-Tuning Matters for Tool Calling
Across our three benchmarks, the untuned LFM2.5 scored between 34.5% and 63.2% tool call equivalence - significantly higher than FunctionGemma’s 10-39% on the same tasks. This speaks to Liquid AI’s architecture and training pipeline. But “better than other small models” is not the same as “production-ready.”
The difficulty of multi-turn tool calling compounds multiplicatively: if a model gets 63% of individual tool calls correct, its probability of getting every call right across a 5-turn conversation drops to roughly 10% (0.63^5). Even the best base score of 63.2% is not viable for real applications.
| Task | Base Accuracy | 2-Turn Accuracy | 5-Turn Accuracy |
|---|---|---|---|
| Shell Command Execution (Gorilla) | 61.4% | ~37.7% | ~8.7% |
| Smart Home Control | 63.2% | ~39.9% | ~10.1% |
| Banking Voice Assistant | 34.5% | ~11.9% | ~0.5% |
How We Addressed It
We used the distil labs platform to fine-tune LFM2.5-350M on three multi-turn tool calling tasks. The pipeline follows the same approach we use across all our models: define the task with a prompt and examples, generate synthetic training data using a large teacher model, validate and filter that data, then fine-tune the student.
Setup
| Parameter | Value |
|---|---|
| Student model | LFM2.5-350M |
| Teacher model | GPT-oss-120B |
| Task type | Multi-turn tool calling (closed-book) |
For the smart home and voice assistant tasks, we used existing datasets that we had previously built for those domains. For the shell command task, we generated 5,000 synthetic training examples from seed data using the full distil labs pipeline. In all three cases, LFM2.5-350M was trained independently from scratch on each dataset.
Training Progress
One thing worth highlighting is how quickly LFM2.5 responds to fine-tuning. Here’s the full epoch-by-epoch progression on tool call equivalence:
| Dataset | Epoch 0 (base) | Epoch 1 | Epoch 2 | Epoch 3 | Epoch 4 |
|---|---|---|---|---|---|
| Gorilla | 61.4% | 98.0% | 97.0% | 98.0% | 98.0% |
| Smart Home | 63.2% | 96.1% | 96.1% | 96.7% | 96.7% |
| Voice Assistant | 34.5% | 86.8% | 92.4% | 95.9% | 95.4% |
After just one epoch of training, the model jumps from unusable to near-production levels on two of three tasks. The voice assistant task - the hardest of the three - peaks at epoch 3 with 95.9% before dipping slightly at epoch 4, a sign that further training offers diminishing returns. Gorilla and Smart Home plateau early and hold steady. This is consistent with what we saw in our 12-model benchmark study, where the previous generation LFM2-350M also ranked among the most tunable (or 🐟-able) models - LFM’s architecture appears particularly receptive to task-specific fine-tuning, absorbing new patterns quickly without catastrophic forgetting.
Our primary metric is tool call equivalence - a binary exact-match score comparing predicted and reference tool calls.
Results: From Capable to Production-Ready
| Task | Teacher (120B) (↑) | LFM2.5-350M Base (↑) | LFM2.5-350M Tuned (↑) |
|---|---|---|---|
| Shell Command Execution (Gorilla) | 97.03% | 61.4% | 98.0% |
| Smart Home Control | 92.11% | 63.2% | 96.7% |
| Banking Voice Assistant | 96.95% | 34.5% | 95.9% |
Shell Command Execution (Gorilla)
The tuned 350M model exceeds the 120B teacher by nearly a full percentage point. This task converts natural language requests into bash commands via structured tool calls, based on the Berkeley Function Calling Leaderboard Gorilla file system task. The base model’s 61.4% shows LFM2.5 already has a reasonable grasp of the task structure, but fine-tuning closes the remaining gap completely. Deployed locally via GGUF in llama.cpp or Ollama, this gives developers a private, offline shell assistant that never sends commands or repository context to an external API.
Smart Home Control
The tuned model beats the 120B teacher by 4.6 percentage points on smart home control. This task converts natural language commands (“turn off the kitchen lights,” “set the thermostat to 72”) into structured function calls, handling multi-turn conversations where users adjust commands or issue sequences. The 63.2% base score is the highest across our three benchmarks, indicating that LFM2.5’s built-in tool calling capabilities give it a head start on constrained function catalogs. This model is a natural fit for embedded deployment on smart home hubs and IoT gateways using the ONNX runtime, where sub-second latency on a low-power NPU means voice commands execute without a round trip to the cloud.
Banking Voice Assistant
The tuned model comes within 1.1 points of the 120B teacher on the hardest task in our benchmark suite. The banking voice assistant routes customer requests to the correct banking function (check balance, transfer money, cancel card, report fraud, etc.) while extracting required parameters. With 14 distinct functions, complex slot types, and ASR transcription artifacts in the input, this task pushes the limits of what a 350M model can do. The remaining gap is narrow enough for production use with an orchestrator handling edge cases - and the model achieves 95.9% accuracy, meaning roughly 1 in 24 calls may need correction. This model targets on-device banking workflows where customer data cannot leave the device perimeter, deployable on mobile NPUs via ONNX or on Apple Silicon laptops via MLX for branch-level kiosk applications.
Datasets & Trained Models
| Task | Dataset | Trained Model |
|---|---|---|
| Shell Command Execution (Gorilla) | distil-labs/distil-SHELLper | distil-labs/distil-lfm25-shellper |
| Smart Home Control | distil-labs/distil-smart-home | distil-labs/distil-lfm25-home-assistant |
| Banking Voice Assistant | distil-labs/distil-voice-assistant-banking | distil-labs/distil-lfm25-voice-assistant |
LFM2.5 vs FunctionGemma: A Stronger Starting Point
We recently published similar results with Google’s FunctionGemma, a 270M parameter model purpose-built for function calling. Comparing the two fine-tuning runs is instructive:
| Task | FunctionGemma Base | FunctionGemma Tuned | LFM2.5 Base | LFM2.5 Tuned |
|---|---|---|---|---|
| Gorilla | 9.9% | 96.0% | 61.4% | 98.0% |
| Smart Home | 38.8% | 96.7% | 63.2% | 96.7% |
| Voice Assistant | 23.4% | 90.9% | 34.5% | 95.9% |
Two things stand out. First, LFM2.5’s base model is significantly stronger across all three tasks, scoring 2-6× higher than FunctionGemma before any fine-tuning. This reflects both the larger parameter count (350M vs 270M) and the strengths of Liquid AI’s architecture for structured output tasks.
Second, the fine-tuned LFM2.5 matches or exceeds fine-tuned FunctionGemma on every task. The voice assistant result is particularly notable: LFM2.5 reaches 95.9% compared to FunctionGemma’s 90.9%, closing 5 more points of the gap with the teacher. Both models end up in the “production-viable” range, but LFM2.5 leaves less on the table.
Train Your Own
The workflow we used for LFM2.5 is generic across multi-turn tool calling tasks. If you have a set of functions you want a small model to call reliably, here’s how to get started:
1. Define your tool schema
Specify the functions and their argument schemas. Be specific about argument types, required fields, and allowed values. See the smart home training data or voice assistant training data for the format.
2. Create seed examples
Write 20-100 example conversations covering your functions, including multi-turn slot filling, intent changes, and error recovery. If your model sits behind ASR, include transcription artifacts in the training data.
3. Train with distil labs
curl -fsSL https://www.distillabs.ai/install.sh | sh
distil login
distil model create my-function-calling-model
distil model upload-data <model-id> --data ./data
distil model run-training <model-id>
distil model download <model-id>You can also use the Distil CLI Claude Code skill to train models directly from Claude Code or Claude.ai.
4. Deploy
The trained model works with Ollama, vLLM, llama.cpp, or any inference runtime that supports GGUF, ONNX, or Safetensors. For quantized deployment on Apple Silicon, use the MLX variants.
If you have a task in mind, start with a short description and a handful of examples; we’ll take it from there. Visit distillabs.ai to sign up and start training, or join our Slack community to ask questions.
This post is part of an ongoing collaboration between Distil Labs and Liquid AI to make fine-tuning LFM models effortless. For more on how the distil labs platform works, see our platform introduction and benchmarking post. For our earlier work with Google’s FunctionGemma, see Making FunctionGemma Work: Multi-Turn Tool Calling at 270M Parameters.