You have an LLM agent in production. It handles restaurant bookings, answers customer questions, calls APIs on behalf of users. It works - but it’s expensive, the latency is noticeable, and throughput is throttled. You want something smaller, faster, and cheaper.
You also have thousands of production traces: real conversations between users and your agent, complete with tool calls and responses. That looks like free labeled training data, so you use it to fine-tune a small model, expecting it to learn your agent’s behavior. You deploy it, and… the downstream metrics look poor. The model doesn’t work as intended.
This is something we have seen time and time again. Training directly on traces doesn’t work as well as you’d expect. The model struggles because production data is never clean - it’s full of errors, inconsistencies, and noise that get baked into the weights during fine-tuning.
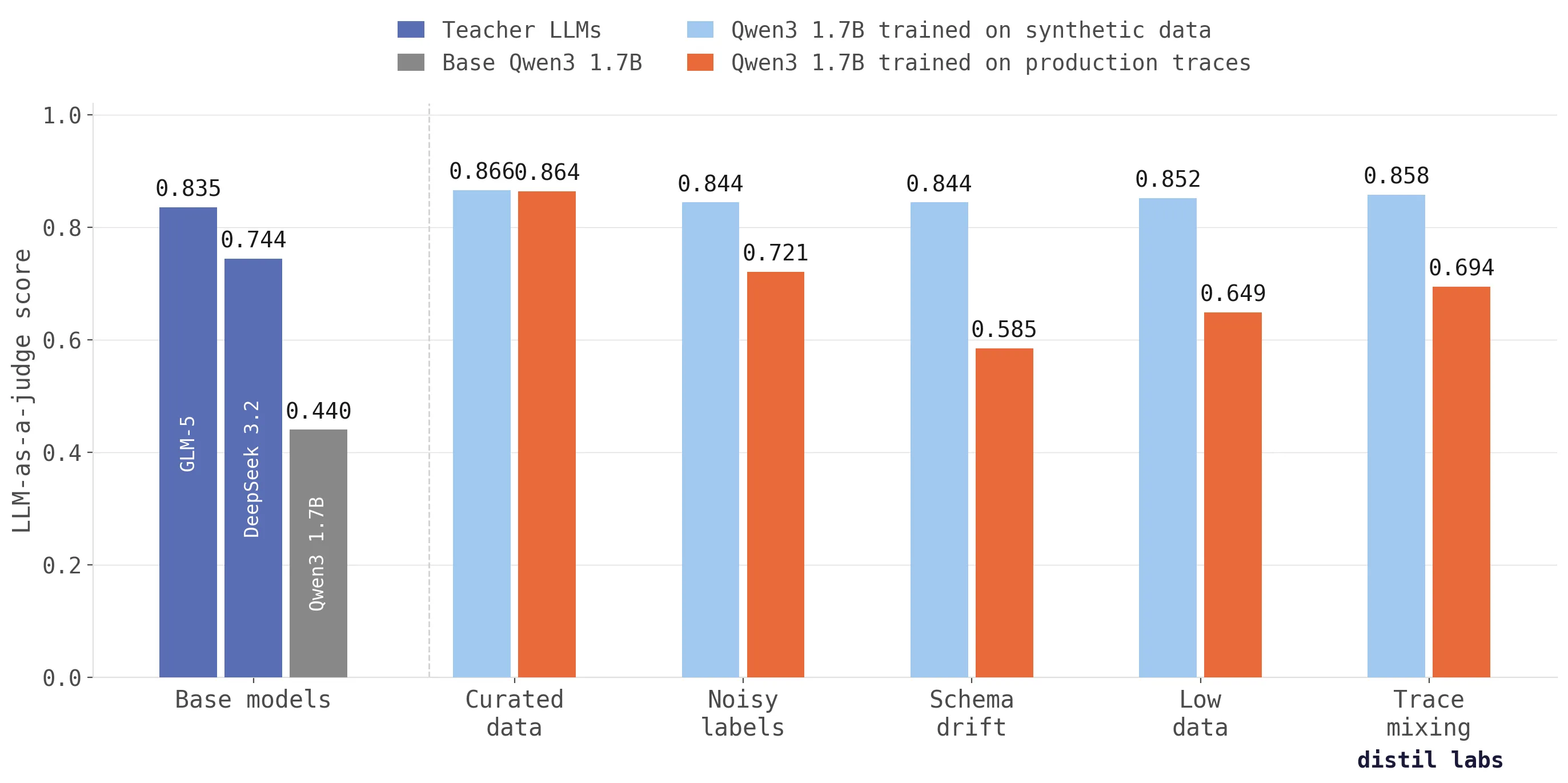
We tested this across five realistic scenarios and the results are clear: the only way to train high-performing SLMs is to use those traces as context for synthetic data generation. This process produces models that score up to 26 percentage points higher in accuracy than SLMs trained on production data. What is more, SLMs (Qwen3 1.7B) tuned on synthetic data outperform frontier teacher LLMs (GLM-5 744B) across every scenario; that is a staggering 437x difference in size!
Why production traces make bad training data
Production traces carry valuable domain signal. They show real user intents, realistic conversation flows, and actual tool usage patterns. But they also carry noise, and that noise takes predictable forms:
Noisy labels. Your agent doesn’t always get it right. It calls the wrong tool, hallucinates parameters, or responds with text when it should have made an API call. In our benchmark, we simulated this by updating 50% of tool calls in the trace set - updating tools to different (but related) ones, replacing service calls with chat responses, and vice versa. This is not extreme: production agents regularly make mistakes, and those mistakes become training signal when you fine-tune directly.
Schema drift. APIs evolve. Function names get renamed, parameters change, new versions get deployed alongside old ones. Your trace logs end up with a mix of schemas - some traces use FindRestaurants with a cuisine parameter, others use search_restaurants with food_type. We simulated this by randomly updating function and parameter names to sensible but different names (e.g. FindRestaurants to search_restaurants) simulating different versions of the same API.
Low data. Early-stage deployments produce only a handful of traces. Five or twenty conversations is not enough to fine-tune a model reliably, especially for multi-turn tool-calling tasks where the model needs to learn complex interaction patterns.
Irrelevant trace mixing. Logging pipelines don’t always separate cleanly by service. Traces from a hotel booking agent end up mixed with restaurant booking traces. In our test, we simulate a system with 5 agents which means 80% of traces came from a different source - using the right function names but with hotel content (room types, check-in dates) instead of restaurant data (cuisine, party size).
Every team running LLM agents in production encounters at least one of these problems. Most encounter several simultaneously.
Results: synthetic data from traces vs. training directly on traces
We benchmarked both approaches across five scenarios using the Schema-Guided Dialogue (SGD) dataset from Google Research - a human-curated collection of over 20,000 multi-turn, task-oriented dialogues. Our target task was a restaurant booking agent with tool-calling capabilities (FindRestaurants, ReserveRestaurant, respond_to_user). Two pipelines, same test set from SGD, and the same student model (Qwen3-1.7B):
- Direct Training: fine-tune the student directly on the raw traces
- Synthetic from traces: use traces as unstructured context to generate clean synthetic training data via a teacher LLM, validate the output, then fine-tune on that
When both pipelines train on curated, human-annotated SGD data, they perform identically (~0.865) - the synthetic pipeline does not degrade performance. But the moment traces carry real-world noise, direct training collapses: scores drop 14-28pp below the gold standard. The synthetic pipeline holds steady, staying within 2pp of the human-labeled ceiling and consistently exceeding the best teacher LLM - GLM-5 at 0.835 (744B) - across every scenario.
| Scenario | Synthetic from traces | Direct on traces | Delta |
|---|---|---|---|
| Curated data (human-annotated) | 0.866 | 0.864 | +0.002 (tie) |
| Noisy labels (50% corrupted tool calls) | 0.844 | 0.721 | +12.3pp |
| Schema drift (randomized function names) | 0.844 | 0.585 | +25.9pp |
| Low data (5 traces only) | 0.852 | 0.649 | +20.3pp |
| Irrelevant trace mixing (80% wrong domain) | 0.858 | 0.694 | +16.4pp |
Metric: LLM-as-a-judge score on ~360 evaluation turn pairs from 34 held-out multi-turn conversations. Best teacher (GLM-5, 744B): 0.835.
Schema drift (+25.9pp) is the most dramatic gap. With 21 randomized function names across traces, direct training simply cannot learn the correct tool vocabulary. The model sees search_restaurants, lookup_restaurants, find_places_to_eat and has no way to know which one is right. The synthetic pipeline reads the task description and tool schema, ignores the wrong names in the traces, and generates clean examples using the correct API.
Low data (+20.3pp) shows the power of synthetic amplification. Five traces expand to roughly 55 per-turn training examples for direct training - far too few. The synthetic pipeline uses those same 5 traces as seed context and generates ~2,000 realistic multi-turn conversations, providing enough training signal to nearly match the curated data ceiling.
Irrelevant trace mixing (+16.4pp) is particularly insidious. The hotel traces use similar names to restaurant function names but very different conversation flow (different message order). Direct training learns the wrong associations for FindRestaurants and ReserveRestaurant. The synthetic pipeline’s validation layer catches structurally invalid traces and corrects any mistakes producing clean conversations.
Noisy labels (+12.3pp) corrupts tool timing in both directions: the agent learns to make API calls when it should talk, and talk when it should act. The synthetic pipeline filters out incoherent traces via relevance and coherence scoring, then generates clean data from the traces that pass.
Across every corrupted scenario, the synthetic approach stays within 2 percentage points of the gold-standard ceiling. Direct training drops 14-28pp below the gold standard.
Why does generating synthetic data from traces work?
The core insight is simple: traces contain domain signal, but that signal is mixed with noise. Instead of training on the noisy mixture, you use traces as context for a teacher LLM to generate new, clean training examples.
Here is what happens in practice. Production traces go into the pipeline as unstructured context data - not as labeled training examples. A teacher LLM reads the task description, the tool schema, and a sample of traces to understand the domain: what kinds of conversations happen, what tools get called when, what user requests look like. It then generates new synthetic conversations that follow the same domain patterns but without the errors, schema inconsistencies, or irrelevant content from the original traces.
A validation layer checks each generated example against the target schema, filters near-duplicates, and removes outliers. The student model trains on the validated synthetic dataset - typically ~2,000 multi-turn conversations generated from as few as 5-40 seed traces.
This works because the teacher LLM extracts the distributional signal from traces (what topics come up, how conversations flow, when tools get called) while being guided by the normative signal from the task description and tool schema (what the correct behavior should be). The traces tell the teacher what the domain looks like; the schema tells it what correct looks like. The result is training data that is both domain-realistic and technically correct.
What this means for practitioners
If you’re collecting production traces to fine-tune a small model, the takeaway is straightforward: don’t train directly on them unless you can guarantee they are consistently high-quality. In practice, that guarantee is impossible without human curation.
The more realistic your traces are - messy, evolving, mixed across services - the more you need a curation and generation layer between collection and training. Without it, you’re teaching your model to repeat your agent’s mistakes with high confidence.
This is especially critical for multi-turn tool-calling agents. A classification model that’s wrong 5% of the time is annoying. A multi-turn agent that makes 5% more errors per turn is a disaster. 95% accuracy on a single turn translates to only 0.95^20 - roughly 35% of 20-turn interactions being fully correct. That’s the difference between a great product and a useless one. Tool timing errors - calling an API when the agent should ask a clarifying question, or chatting when it should act - compound across turns and are among the hardest to debug because the model’s output looks syntactically correct.
Experiment details
For readers who want the full methodology, all data and code can be found in our benchmarking repository.
Dataset. The Schema-Guided Dialogue (SGD) dataset from Google Research contains over 20,000 human-curated, multi-turn dialogues across 20 domains. We used the Restaurants_1 service as our target task: a booking agent that uses FindRestaurants, ReserveRestaurant, and respond_to_user tools. After reserving 34 conversations (40 traces, committee-rewritten) as a shared test set, we had 327 clean Restaurants_1 traces as our canonical training source.
Student model. Qwen3-1.7B, fine-tuned with LoRA (rank 64).
Evaluation. LLM-as-a-judge (GPT-OSS-120B) scoring on ~360 expanded turn pairs from the 34 held-out conversations. We evaluated multiple large models as teachers on the same test set to establish performance ceilings:
| Teacher Model | LLM-as-a-judge | Std |
|---|---|---|
| GLM-5 | 0.835 | 0.006 |
| Qwen3-235B | 0.768 | 0.018 |
| GPT-OSS-120B | 0.765 | 0.020 |
| MiniMax-M2 | 0.762 | 0.010 |
| DeepSeek-3.2 | 0.744 | 0.014 |
Note that our fine-tuned 1.7B student (0.844-0.866) exceeds every teacher model across all scenarios, including GLM-5 (744B) - the best-performing teacher.
Scenario construction. Each scenario starts from the 327 clean traces and applies a specific corruption:
- Curated data: No corruption. Training data comes from the same human-annotated SGD source as the test set. Both pipelines train on the same 327 clean traces.
- Noisy labels: 50% of assistant tool calls corrupted. Service tools get swapped (FindRestaurants to ReserveRestaurant), replaced with respond_to_user messages, or given parameters from different traces. respond_to_user messages get replaced with random service calls. This corrupts both tool choice and timing.
- Schema drift: 50/50 mix of Restaurants_2 traces (different parameter names like
category/locationinstead ofcuisine/city) and Restaurants_1 traces with per-trace randomized function names (6 alternatives each for FindRestaurants, ReserveRestaurant, respond_to_user) and parameter names. - Low data: 5 traces subsampled from the clean set. No corruption - the challenge is extreme scarcity.
- Irrelevant trace mixing: 80% Hotels_1 traces (message order changed) + 20% clean Restaurants_1 traces. Hotels content uses the correct function names but with hotel semantics (room types, check-in dates) in random order.
Synthetic data pipeline. Generate a reference seed data by passing a subset of traces (~60) through relevance and coherence filtering, committee-based conversation rewriting. Rest of traces are used as unstructured context for synthetic data generation. The teacher LLM (GLM-5) generates ~2,000 multi-turn conversations per scenario. Validation filters check schema conformance, remove near-duplicates, and reject length outliers.
Direct training pipeline. Raw traces are converted directly to training examples with no filtering, relabeling, or augmentation.
Both pipelines use the same test set, student model, training hyperparameters (4 epochs, learning rate 5e-5), and evaluation harness.
Conclusion
Production traces are a valuable source of domain knowledge, but they are not training data. The gap between “data that describes your domain” and “data you should train on” is where most fine-tuning projects fail. Treating traces as context for synthetic data generation - rather than as labels for supervised learning - closes that gap.
distil labs automates this process: feed in your traces and a task description, and the platform handles filtering, synthetic generation, validation, and fine-tuning. The result is a small, accurate model that captures the domain knowledge in your traces without inheriting their mistakes.
If you have a task in mind, start with a short description and a handful of examples; we’ll take it from there. Sign up to get started, or check out our docs to learn more.