Introduction
Large language models changed the way we build AI products but they are not suited for all applications and environments. In many industries, you can’t always process data in the cloud. You need models that stay private, run fast, and fit on your hardware - without compromising on accuracy. That’s the question we put to the test: can distilled small language models (SLMs) consistently meet a strong teacher’s bar (LLM) across varied tasks?
The short answer is yes. With task-specific distillation, compact students routinely track and surpass teacher LLMs while being dramatically smaller and faster. In this post we’ll give you a high-level overview of how to create high-quality SLMs without breaking the bank and show performance on a few open benchmarks. You’ll see that, counterintuitively, fine-tuned small models can not just match, but exceed, the performance of LLMs on specific tasks.
How it works
distil labs turns a few-shot learning prompt into a production-ready small model: a strong teacher LLM generates in-domain examples, we rigorously filter and balance that synthetic data, then fine-tune a compact SLM to mirror the teacher’s behavior. The student is evaluated on a held-out dataset and packaged for your runtime (vLLM, Ollama, on-prem/edge) - yielding teacher-level performance in a tiny, fast, private model. More details can be found in our previous blogpost introducing the platform.
Distillation Pipeline Benchmarks
To validate that our pipeline works across domains, we evaluate it on a varied mix of datasets and tasks. The objective is consistent: for each domain, a distilled small model should match-or come within striking distance of a strong cloud LLM (teacher model) while being dramatically smaller and faster.
Results
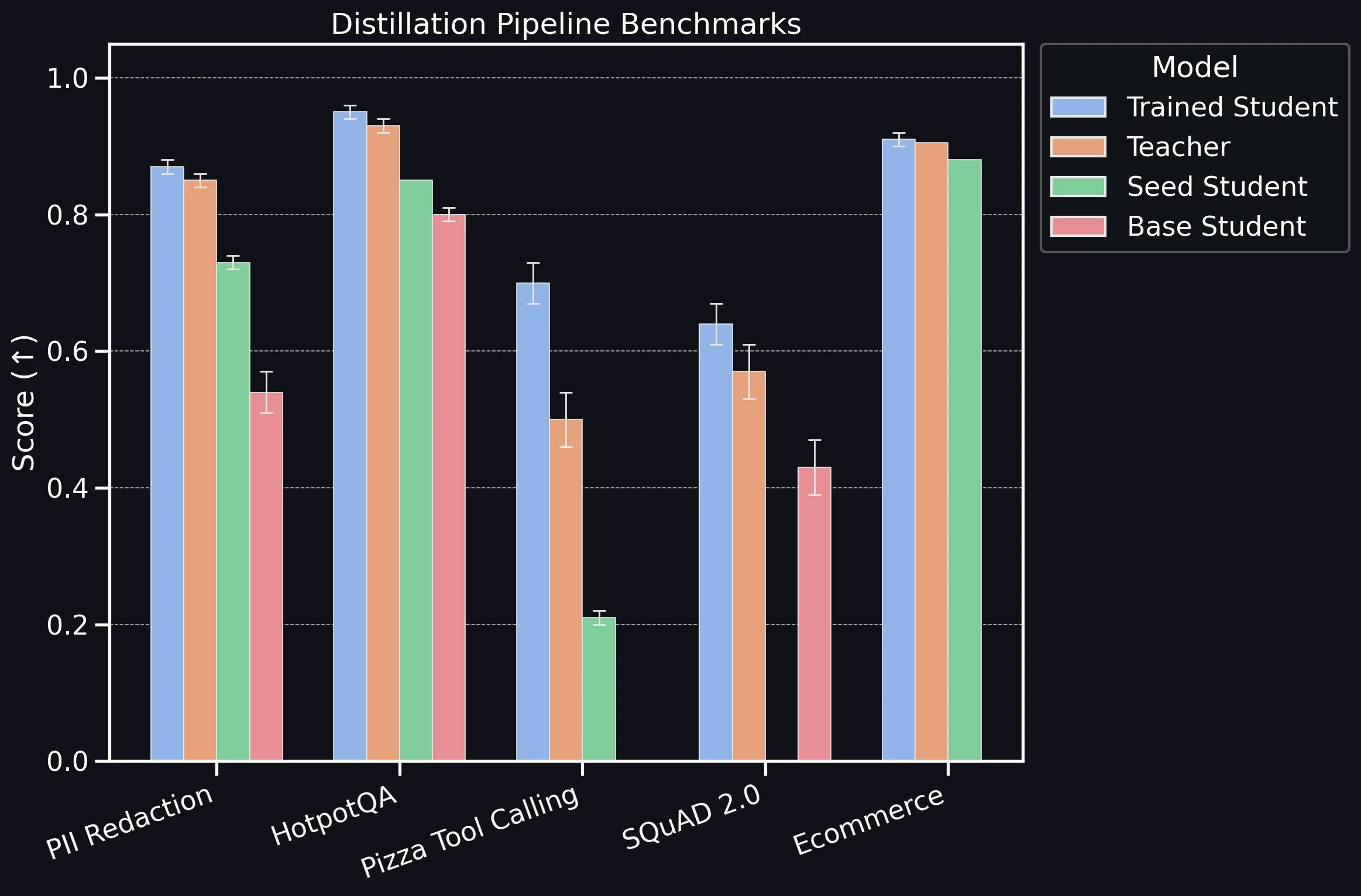
In our benchmarks, the teacher is a strong cloud LLM, the trained student is a compact SLM fine-tuned with our platform, the base student is the SLM prompted for the task with no fine-tuning, and the seed student is an SLM trained only on the initial labeled set.
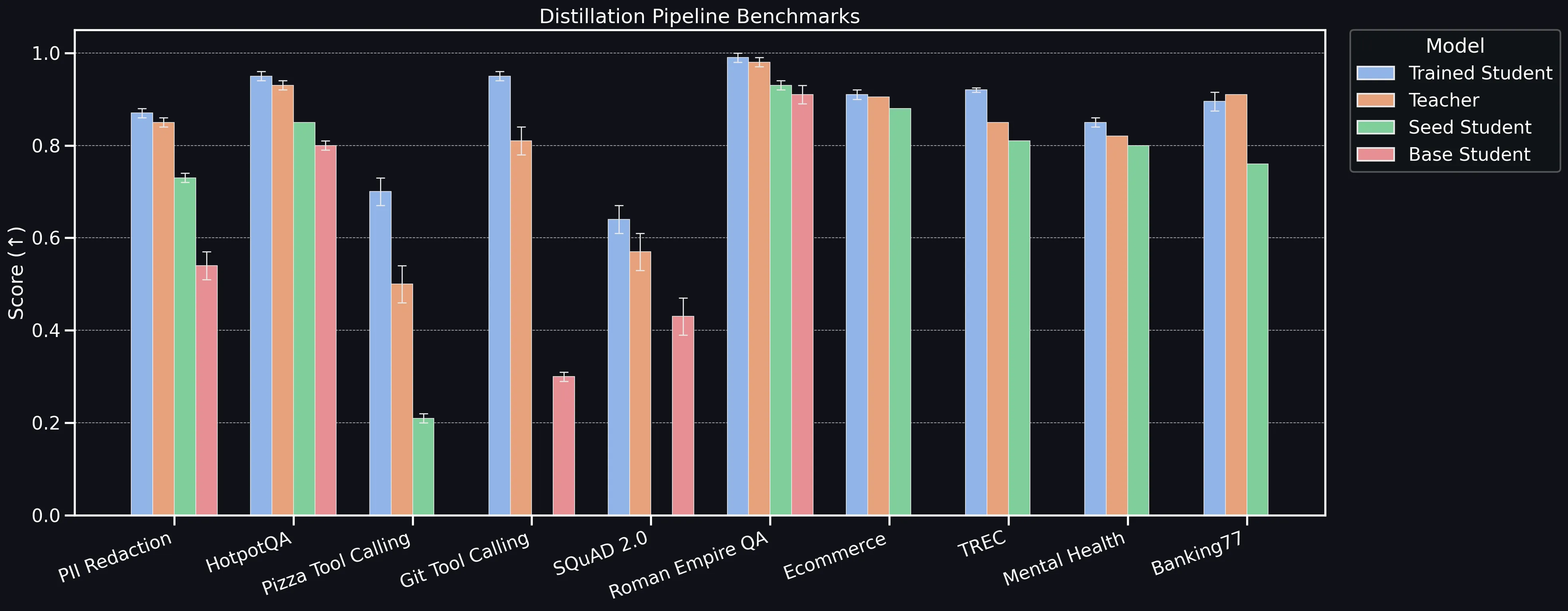
Across all benchmarks, the distilled student consistently outperforms the seed and base baselines and reaches or exceeds the teacher on eight datasets. The only exception is Banking77 where the student sits within 1 percentage point of the teacher - i.e., within the reported confidence interval. The pattern is clear: task-specific generation + curation produces small models that match or closely track cloud LLMs while being dramatically smaller and faster.
The decisive gaps versus base models show why the pipeline matters: specializing SLMs (trained student) moves the needle much more than prompt tuning baselines (base student). Practically speaking, this means you can only get so far with prompting and fine-tuning is necessary to unlock really accurate small local agents.
If you prefer a table view, you can find it below. All values are averaged over 3 runs, standard deviation is provided where >=0.005
| Dataset | Teacher (↑) | Trained Student (↑) | Base Student (↑) | Seed Student (↑) |
|---|---|---|---|---|
| Ecommerce | 0.905 | 0.91 +/- 0.01 | NA | 0.88 |
| TREC | 0.85 | 0.92 +/- 0.005 | NA | 0.81 |
| Mental Health | 0.82 | 0.85 +/- 0.01 | NA | 0.80 |
| Banking77 | 0.91 | 0.895 +/- 0.02 | NA | 0.76 |
| PII Redaction | 0.85 +/- 0.02 | 0.87 +/- 0.01 | 0.54 +/- 0.03 | 0.73 +/- 0.01 |
| HotpotQA | 0.93 +/- 0.01 | 0.95 +/- 0.01 | 0.8 +/- 0.01 | 0.85 |
| Roman Empire QA | 0.98 +/- 0.01 | 0.99 +/- 0.01 | 0.91 +/- 0.02 | 0.93 +/- 0.01 |
| Pizza Tool Calling | 0.50 +/- 0.04 | 0.70 +/- 0.03 | 0.0 | 0.21 +/- 0.01 |
| Git Tool Calling | 0.81 +/- 0.03 | 0.95 +/- 0.01 | 0.03 +/- 0.01 | |
| SQuAD 2.0 | 0.57 +/- 0.04 | 0.64 +/- 0.03 | 0.43 +/- 0.04 | NA |
Benchmark details: baselines
We compare four reference points under the same preprocessing, seed split, and evaluation harness:
- Teacher (reference). Teacher (LLama3 70B) evaluated with a fixed prompt and *k-*shot examples drawn only from the training split (never test). This establishes the performance level we aim for with a much smaller student.
- Trained Student (ours). Student (Llama3 3B) trained on seed + curated synthetic data generated by the teacher. Making sure this strategy scores as close as possible to the teacher is the main goal of our benchmarking.
- Seed Student. Student (Llama3 3B) trained only on the initial seed set. Shows what you get without synthesizing additional data.
- Base Student (lower bound). Student (Llama3 3B) prompted with the task description. Shows the performance you can get with prompt tuning.
Fairness & controls. All baselines share the same held-out test split and use the same hyperparameters for model training.
Benchmark details: datasets & metrics
We list each dataset with its primary evaluation metric. A fixed held-out test split is reserved for all methods.
We evaluated five families of tasks to reflect common enterprise patterns:
- Classification (e.g., intent, categorization) where accuracy is the main metric.
- Information extraction, judged with a binary LLM-as-a-Judge prompt that inspects both references and predictions.
- Open-book QA that rewards retrieval-grounded reasoning and factual precision.
- Tool-calling, where we build agents based on small models.
- Closed-book QA, where context is withheld at inference and the model must internalize knowledge during training.
We keep the setup uniform and conservative: fixed data splits, a consistent evaluation harness, and straightforward scoring rules.
Classification Datasets
Unless otherwise specified, all datasets use accuracy as the evaluation metric.
- The Text REtrieval Conference (TREC) Question Classification dataset contains example phrases classified into one of 8 categories based on content.
- BANKING77 dataset, which contains pairs of customer inquiries and the corresponding category of said inquiry.
- E-commerce dataset contains product descriptions and their corresponding categories, focusing on the four main categories that represent ~80% of typical e-commerce inventory:
- Workplace incident dataset that contains injury narratives and their corresponding classification according to the Occupational Injuries and Illnesses Classification System (OIICS). The dataset focuses on seven major categories that encompass the primary types of workplace incidents
- Mental health dataset contains user comments and their corresponding mental health classifications across four main categories: Normal, Depression, Anxiety, Bipolar.
Information Extraction Datasets
We use binary LLM-a-a-Judge score prompted with the prediction, reference and the task description
- PII redaction dataset maps customer/support texts to their redacted versions that removes sensitive personal data while preserving operational signals (order IDs, last-4 of cards, clinician names). Discussed above.
Open Book QA Datasets
We use binary LLM-as-a-Judge score prompted with the prediction, reference and the task description
- HotpotQA question answering using dataset focuses on developing models that can answer complex, multi-hop questions requiring reasoning across multiple documents.
- Roman Empire QA is a simple dataset we used to showcase training of 100M parameter models - all larger LLMs should solve it, but still acts as a good litmus test for any model training.
Tool Calling Datasets
Using text-based evaluation metrics like ROUGE isn’t ideal here so to mitigate this, we convert target and predicted outputs to Python dicts, compare them using the standard equality function and report either 0 (no match) or 1 (equivalent dicts) for each example.
- In the Pizza Tool Calling tasks, we created a synthetic dataset to evaluate tool calling performance for a pizza making problem. The setup: given a pizza recipe and the current state of preparation, suggest the next step using one of the predefined tool calls. As an example, given the following query:
Hawaiian recipe: spread tomato sauce on the base, add mozzarella, ham, and pineapple chunks, bake at 240°C for 10 minutes. Dough is stretched and ready.The next step is to spread tomato sauce on the dough using the following function call:{"name": "add_sauce", "parameters": {"sauce": "tomato"}} - The “Git Tool Calling” dataset shows the performance of the task of turning plain-English queries into git commands. The language model is asked to output a function call based on a predefined schema, which is a subset of available git commands like e.g.
make a commit that says 'feat: add search box' -> {"name": "git_commit", "parameters": {"message": "feat: add search box"}}
Closed Book QA Dataset
We use binary LLM-as-a-Judge score prompted with the prediction, reference and the task description. For those tasks, we do not provide the score for seed-tuning since it does not really help with embedding the knowledge into the student, so no improvement over the base student is expected.
- SQuAD 2.0: To create this dataset for a closed-book QA setting, we leverage a popular open-book QA dataset: SQuAD 2.0. To make it closed-book, we extract the context column and use this as unstructured data. What remains are the question-answer pairs (without context). The aim of the distillation pipeline is to embed the knowledge from the context directly into a model so that we can do question-answering without having to pass context at runtime.
Conclusion
If you care about shipping private, low-latency AI without conceding accuracy, small models can carry the load - provided you give them the right training signal. These benchmarks show that disciplined generation and curation reliably deliver teacher-level performance in compact students, unlocking deployment flexibility from on-prem racks to edge devices.
If you have a task in mind, start with a short description and a handful of examples; we’ll take it from there. Use the link at the top to sign up and start straight away!