
TL;DR
- Most agentic AI workflows are chains of narrow, repeatable tasks; using an LLM at every node adds unnecessary latency, cost and energy use.
- Small language models (<10B params) can run on common hardware with low latency, enabling better data privacy.
- When fine-tuned to a well-scoped job, SLMs can match (or beat) much larger LLMs because they stay within task boundaries.
- Recent techniques (synthetic data generation, self-improvement, knowledge distillation) slash the data and time needed to customize SLMs.
- distil labs turns this into practice: data-efficient distillation for classification, QA, function calling, and information extraction, with more modalities coming.
- Use SLMs for focused tasks, high throughput applications, and on-device/VPC requirements; reserve LLMs for open-ended reasoning and broad synthesis.
Introduction
Large language models radically lowered the barrier to building AI features. Prototyping by prompting an LLM became commonplace and replaced the time-consuming process of creating bespoke machine learning models.
This new capability led to the creation of a new generation of “GPT-wrapper” startups which create agentic AI systems powered by large language models.
But is this shift to ever larger foundational models aligned with the functional requirements of the agentic AI systems we are building?
In this blogpost we outline how you can combine the best of both worlds: speed of development of LLMs but control and efficiency machine learning. This blueprint offers a more efficient and environmentally sustainable way of designing AI systems.
The Problem: LLMs Are Overkill for Most Agent Nodes
When taking a closer look, we quickly discover that advanced Agentic AI applications decompose complex goals into a workflow of specialized, modular tasks: route an intent, extract fields, call a tool, log a result, etc.
Most of the tasks performed as part of an AI agentic system are narrow, utilizing only a very small scope of an LLM’s capabilities. At the same time, using an LLM in every node makes one pay a tax in latency, cost, and energy.
In contrast, small models focused on narrow tasks, tend to be faster, cheaper, and shift the inference loads to the hardware on which they can be deployed, unlocking design patterns that help us keep our data secure.
The Alternative: Small Language Models
What is a “Small” Language Model (SLM)?
Since this categorization is relative, we decided to define an SLM as a language model that fits on common consumer hardware for inference. As of 2025, we deem models below 10B parameters as “small” (SLMs), and those above as “large” (LLMs).
There are entire families of small models available out there, providing us with the ability to choose from a spectrum of sizes:
- Llama 3 (1B, 3B, 8B)
- Phi-3/Phi-4 (~3.8B, ~7B)
- Qwen2 (0.5B, 1B, 7B)
- SmolLM2 (135M, 360M, 1.7B), SmolLM3 3B
- Gemma (270M, 1B, 2B, 4B, 7B, 9B)
- Mistral (7B)
- Granite (8B)
In the coming weeks we will be releasing benchmarks about which small models perform best on different types of tasks, follow Selim and Jacek on LinkedIn to learn about them.
Are small language models (SLMs) good enough to compete with LLMs?
In a recent study NVIDIA researchers make the case that small language models have the right characteristics and sufficient performance could become the backbone of the next generation of agentic AI applications.
Even though small model capabilities improved tremendously in the last few years, a difference in accuracy still exists between small and large models when benchmarked across a broad set of datasets.
This is if we were to compare an out-of-a-box large model vs small, which does not seems like a fair comparison.
One of the core advantages of SLMs is that they are more “flexible”. In practice this means that it is easier to fine-tune them and improve their performance on narrowly defined tasks.
When fine-tuned for a single job (e.g., PII redaction, function selection, docket classification), SLMs deliver LLM-level accuracy with far lower variance, latency, and cost.
→ distil labs: benchmarking the platform
Large models still win at open-ended reasoning and broad synthesis; the mistake is assuming you need that at every node of an agent.
Wait, but doesn’t fine-tuning require plenty of upfront investment?
Challenges of model fine-tuning – mostly done by researchers and people without alternatives
Historically, model fine-tuning required 10,000+ labelled datapoints curated by subject matter experts, infrastructure, and in-house knowledge to iterate on improving performance.
The entire process easily required weeks if not months, accumulating significant upfront time & capital investments without a clear idea of what performance to expect.
This resulted in mostly universities and a very narrow group of companies that were willing to invest into research to unlock model performance improvements.
distil labs: SLM fine-tuning with just a prompt
With distil labs, fine-tuning a small language model feels a lot like building with an LLM:
- Write a prompt (optionally attach any data for context)
- Iterate based on LLM feedback
- Review preliminary results within minutes
Under the hood, our proprietary platform trains a high-accuracy, task-specific model from AI feedback.
You prototype with an LLM’s speed, then ship with SLM economics: sub-second latency, lower cost, stricter guardrails, and private-by-default compute.
This brings model fine-tuning into 2025, so anyone on your team can deploy an agentic workflow based on specialized SLMs within hours.
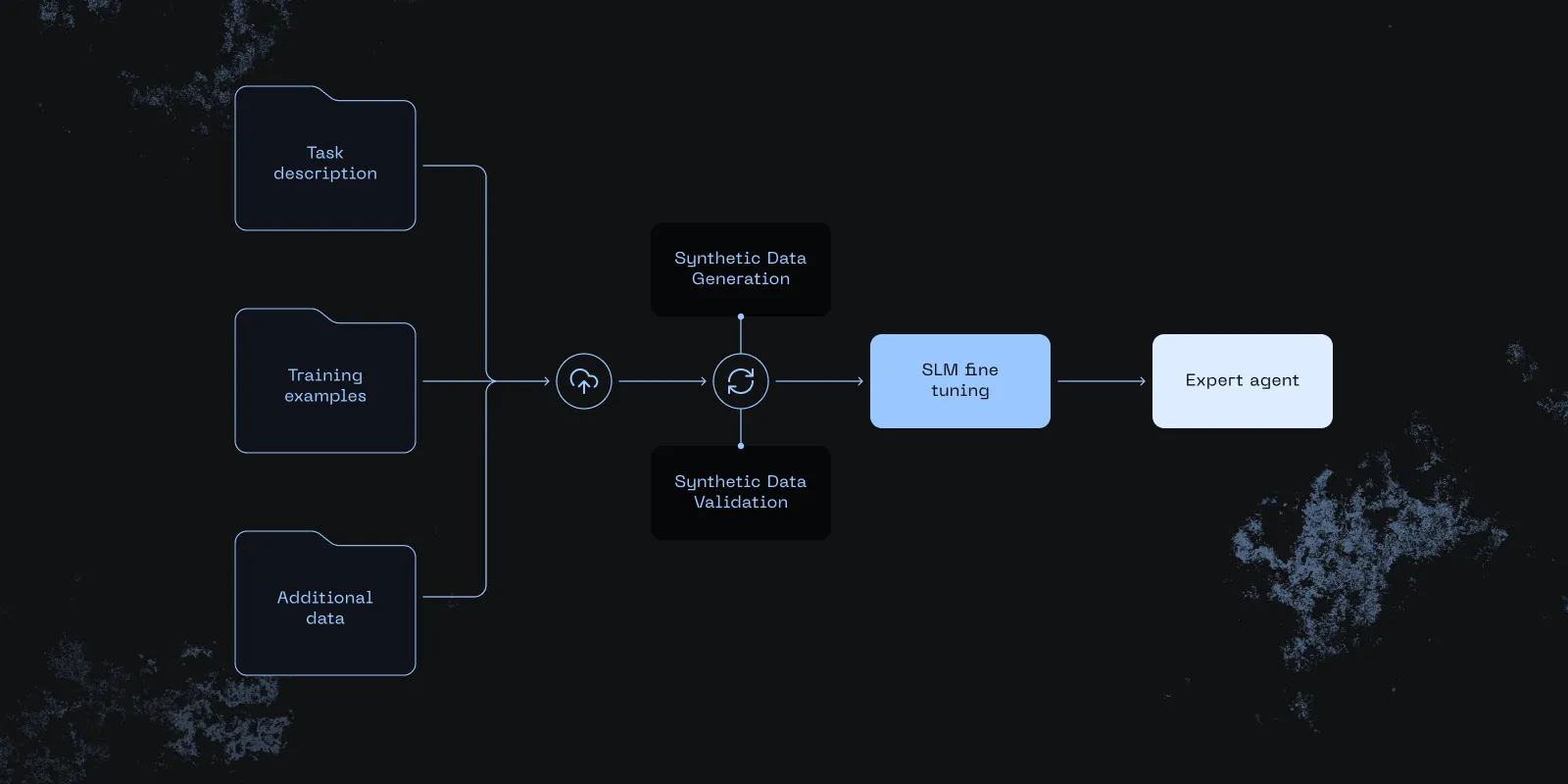
→ To learn more about how the platform works in practice check out the more in-depth post by our CTO: small expert agents from 10 examples.
The platform enables model distillation for a variety of tasks (classification, open-book QA, closed-book QA, function calling, information extraction) and many more on underway (image & video processing use cases using VLM distillation).
Should I choose an SLM or LLM for my tasks?
Treat SLMs and LLMs as tools, not ideologies. If your task is narrow, latency-sensitive, or privacy-constrained default to an SLM and fine-tune. If your task is open-ended, cross-domain, or you can tolerate the latency, choose an LLM. The table below summarizes the trade-offs.
The following table gives breaks down the decision factors that illustrate how to select the right model type for your use case.
| Decision factor | Prefer SLM when… | Prefer LLM when… | Why this matters? |
|---|---|---|---|
| Task complexity & reasoning | Narrow, well-defined tasks: extraction, tagging, routing, simple Q&A, short summaries | Open-ended synthesis, multi-step reasoning, planning, complex code/data analysis, creative ideation | Bigger models generally reason and generalize better; small ones excel at focused, repeatable tasks |
| Knowledge breadth / ambiguity | Domain-specific, templated prompts with clear intent | Broad, cross-domain queries with unclear intent | LLMs handle ambiguity better; SLMs shine with tight prompts |
| Hallucination tolerance / tool use | You need strict, deterministic behavior (tool calling, classification) | Some creativity is fine; you’ll pair with retrieval/validation | SLMs are easier to constrain so their outputs adhere to pre-defined rules. |
| Privacy / data residency | Processing sensitive data, must run on-device/on-prem or in strict VPC | Cloud processing is OK | SLMs fit constrained environments and offline use |
| Latency | Tight SLAs / near-real-time UX (e.g., <~200 ms) | Seconds are acceptable (e.g., analysis, drafting) | SLMs can run fast, often on-device; LLMs are slower due to size |
| Cost per request | Ultra-low cost at scale is required, handling massive volumes | Higher budget per call is acceptable due to low volume | SLM inference is cheaper and they are easier to scale horizontally; LLMs cost more per token |
| Customization | You want the model to learn new skills and make sure it performs well on your specific use case. | You are satisfied with model accuracy and are not planning to inject domain-specific knowledge beyond RAG | SLMs are easier to fine-tune and evaluate (when their scope is kept narrow). |
| Deployment footprint | You are constrained on the hardware you can use (CPU-only, small edge devices, …) | Cloud inference is OK or able to provision large GPU clusters | SLMs fit limited memory/compute |
| Energy / sustainability | Minimizing energy is key | Not the primary constraint | SLMs consume less power, especially on device |
What are the common use cases for SLMs?
Although the applications for SLMs are very broad, there are certain industries with a higher concentration of use cases (below). While some of them are can be generalized across companies, the most interesting needs for small models are bespoke, and in such cases the distil labs platform has to opportunity to show its full potential.
Cybersecurity
- Alert/log triage: summarize SIEM/SOAR alerts; route by severity/use-case
- Phishing & malware intent classification: label emails/URLs; flag indicators
- DLP/PII detection at the edge: redact sensitive data before storage or external use
Financial services
- KYC/KYB document extraction (names, addresses, IDs, dates)
- AML alert triage summaries to reduce false positives
- Transaction labeling & merchant normalization for PFM and risk
Healthcare
- Clinical intake → structured fields (meds, allergies, problems)
- On-device dictation cleanup (punctuation, formatting) for notes
- Information extraction from medical documentation
Insurance
- Claim severity/line-of-business routing
- Policy clause extraction; coverage checks
- Fraud signal pre-screen (rule-augmented)
Conclusion
Agentic systems don’t need an LLM everywhere. Start with LLMs to explore capabilities, then distill the stable skills into SLMs for each node and keep LLMs only where broad reasoning is essential. The result is faster, cheaper, greener, and more controllable AI—made practical by data-efficient SLM fine-tuning.
Mission
At distil labs we are on a mission to enable anyone to seamlessly create custom small language models, regardless of the resources they have available.
Sources & further reading
- Belcak et al., “Small Language Models are the Future of Agentic AI.” Position + LLM→SLM agent conversion outline. arXiv
- Sudalairaj et al., “LAB: Large-Scale Alignment for ChatBots.” Taxonomy-guided synthetic data; multi-phase tuning with reduced human labels. arXiv
- Wang et al., “Self-Instruct.” Annotation-light instruction tuning via synthetic data. arXiv
- Bai et al., “Constitutional AI.” Self-critique and AI feedback for alignment. arXiv
- Li et al., “Self-Alignment with Instruction Backtranslation.” Auto-labelling web text + self-curation. arXiv
- Hinton et al., “Distilling the Knowledge in a Neural Network” arXiv