If your team runs an LLM-powered agent in production, every request it handles is a test case you never had to write. That trace data describes your problem space better than any hand-crafted dataset: the vocabulary your users actually use, the edge cases that show up in the real traffic, the real distribution of requests.
We take your production traces and use them to train a small language model purpose-built for your task. The model is not trained on your traces directly — we feed them to a large teacher model as domain context to generate >10,000 high-quality synthetic training examples grounded in your real traffic. The model trained on those examples is a compact specialist that knows your domain, your schemas, and your users’ phrasing.
You provide:
- Production traces (unlabeled) from your existing agent
- A description of your task — your current LLM prompt is a good start
distil labs handles everything else: data curation, synthetic data generation, fine-tuning, evaluation, and deployment.
Technical walkthrough and demo repository can be found in: github.com/distil-labs/distil-dlthub-models-from-traces
Results
We ran this on an IoT smart home function-calling agent. Starting from 1,107 production traces and no manual labeling, we trained a 0.6B specialist model.
| Model | Parameters | Exact Match |
|---|---|---|
| Teacher (120B general-purpose) | 120B | 50.0% |
| Base student (no fine-tuning) | 0.6B | 10.26% |
| Tuned student (distil labs) | 0.6B | 79.49% |
The 0.6B specialist beats the 120B teacher by 28 points on exact structured match. The teacher is a highly capable general-purpose model — it scores lower because it has never specialized in this domain. The student wins because task specialization consistently beats model size for bounded, well-defined tasks.
The inference tax you don’t have to pay
Frontier LLMs keep getting better and cheaper: GPT-4o mini costs $0.15 per million input tokens, Gemini 2.5 Flash is $0.10. At these prices, is there still a case for running your own small models?
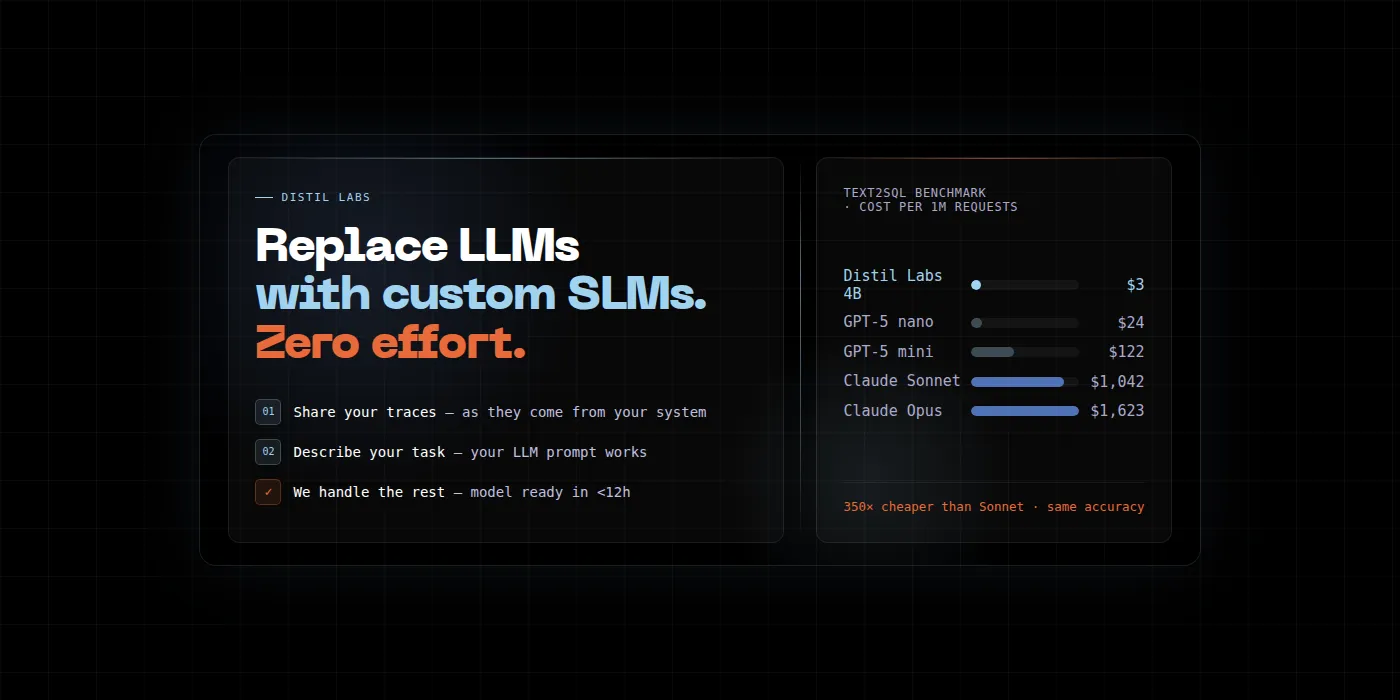
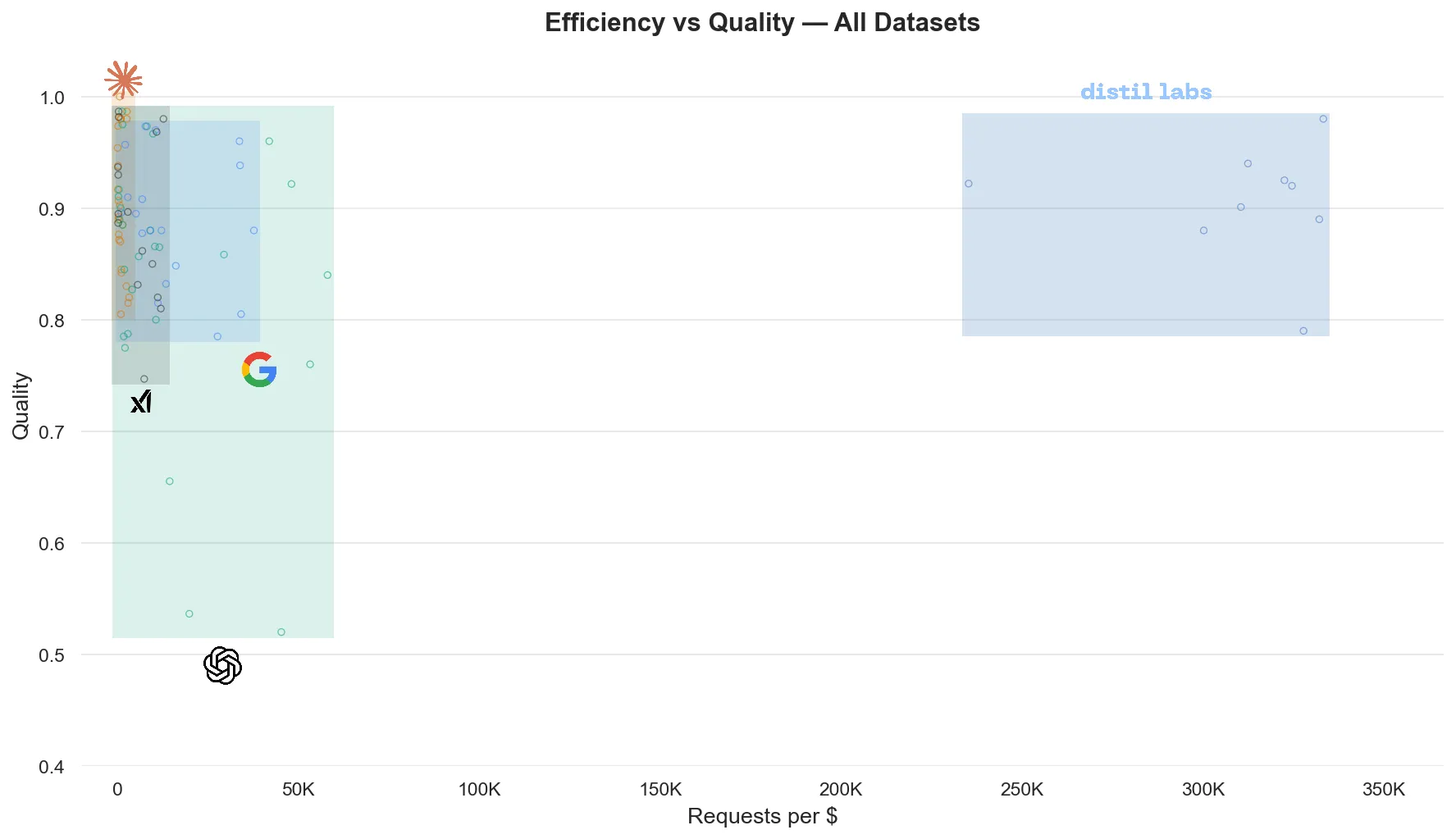
We ran comprehensive benchmarks across 9 datasets spanning multiple task categories to find out. For bounded, well-defined tasks - the kind your production agent is already handling - small specialized models are faster, cheaper, and match or exceed frontier quality. The cost gap is 10x or more, and it compounds with every request.
Full analysis: The 10x Inference Tax You Don’t Have to Pay
How can we work with you
Our solution engineering team handles the process end to end. You share your traces and describe the task; we configure the pipeline, run the training, and deliver a benchmark comparing the specialist against your current system — before you commit to anything.
Models are ready in under 12 hours. No ML expertise required on your side.
Get in touch: distillabs.ai