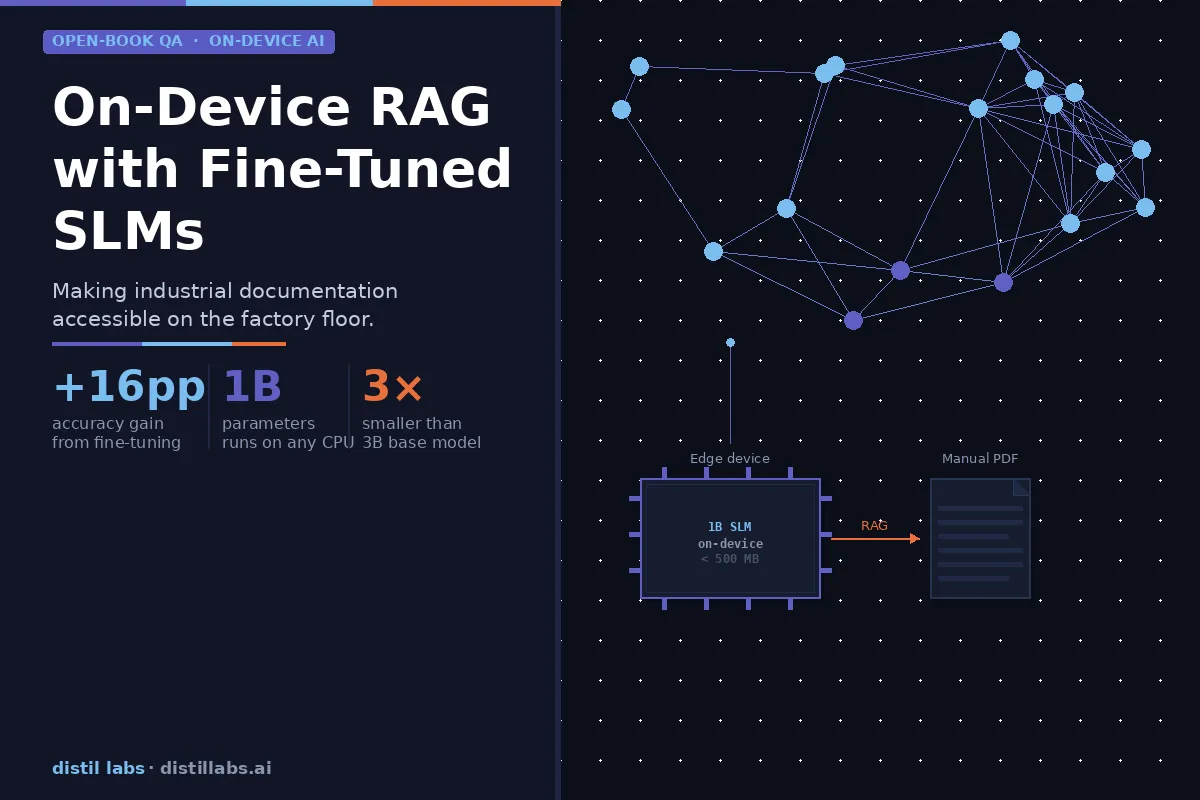
In our other articles, we’ve looked at how fine-tuned Small Language Models can handle tasks like intent classification, PII redaction, and function calling for agentic workflows. These are clear cut cases where small distilled models consistently match the performance of much larger models. But how do SLMs perform at RAG (Retrieval Augmented Generation)?
In this case, models need to answer questions based on context that is provided at inference time. This is also known as open-book question answering, and it can be a little trickier for small models to handle since there is a human in the loop and the inputs can be unpredictable.
On first glance, you might wonder why you’d need SLMs at all, since an LLM (frontier or open-source) will do fine for most RAG use cases. There are exceptions though.
We’ve already covered how SLMs are important for environments with limited connectivity, limited hardware resources, and strict privacy requirements. The use case we’ll look at here is somewhat speculative but still grounded in the reality of industrial networks which have strict security requirements and limited connectivity to the wider internet.
Let’s recap how these environments typically look from a network perspective.
Industrial networks have multiple layers of security
It can be difficult to get RAG to work when you have a locked down network with different layers of security. Consider the classic Purdue model for industrial control system (ICS) security. It divides systems into levels (usually 0 to 4, sometimes with a 3.5 in between), ensuring that hackers breaching one area (like an office email) can’t easily jump to the machines controlling valves or motors. This “defense in depth” uses firewalls and rules to control data flow upward, while keeping risky internet access out of the bottom operational technology layers.
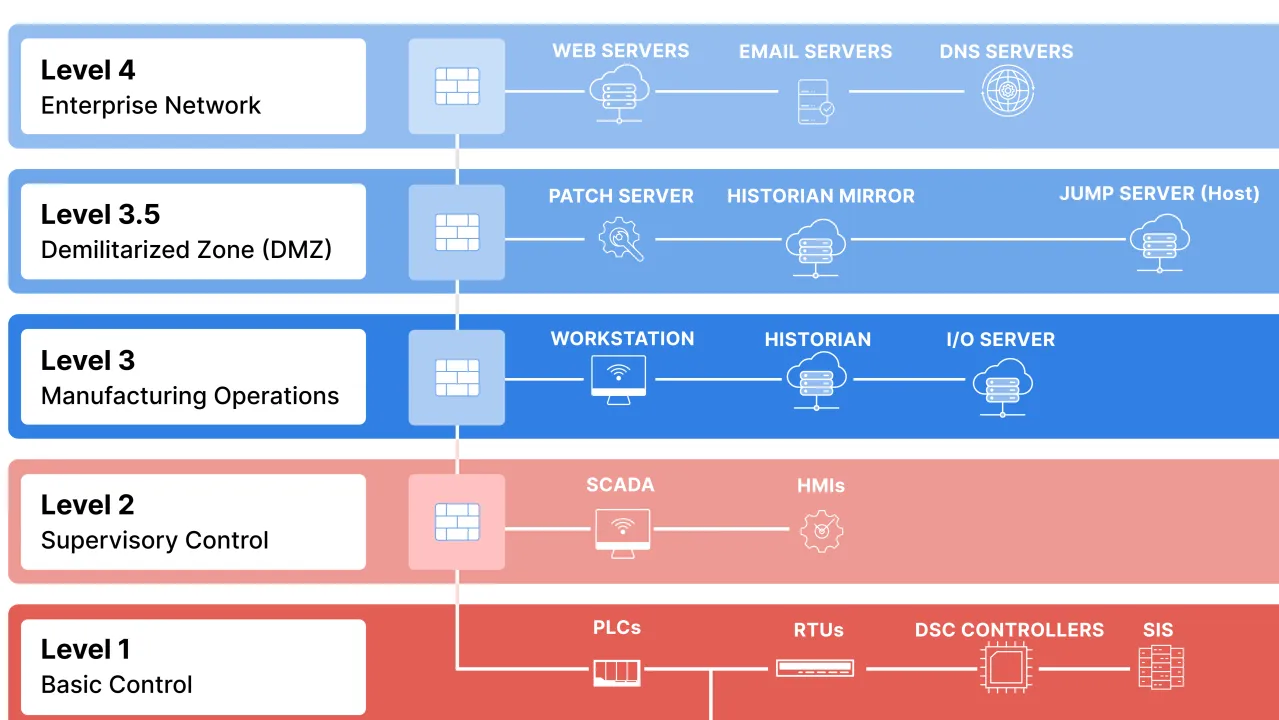
Picture Credit - Fortinet (taken from this post)
Given this layered system, you can understand why it might be difficult to use a cloud-based LLM for inference (even from an enterprise grade service like AWS Bedrock or Azure OpenAI). It would be better to host an open source LLM at level 2 so no contact with the outside world is required. However, you’re going to need a powerful server with a decent (and expensive) GPU. You might have a hard time convincing the procurement department to allocate budget for what could be considered a “nice to have” use case. An SLM on the other hand, can run on fairly low-spec hardware.
What value can RAG add in Industrial Settings?
Industrial equipment ships with extensive documentation: user manuals, signal references, troubleshooting guides, maintenance procedures. The information operators need is almost always written down somewhere. The problem is finding it.
A CNC controller manual might run to 1,200 pages. When an alarm fires and production stops, nobody has time to Ctrl+F through a PDF, cross-reference three sections, and piece together the answer. Engineers generally have more pressing things to do than go and comb through a manual.
RAG could change this. Instead of searching through documents, you ask a question: “What does alarm 4571 mean and how do I clear it?” The system retrieves the relevant passages and synthesizes an answer—accurate, contextual, in seconds. The documentation becomes accessible in a way that PDF search never achieved.
The potential of RAG for OEMs
Many forward-thinking automation and software engineers are already exploring the potential of RAG in industrial settings, but most PoCs are still based on a centralized architecture where multiple clients use a centralized model for inference.
But on-device RAG at the edge is also a promising use case, especially for equipment manufacturers. Take CNC machines for example. These devices typically have decent HMIs that enable you to search for basic technical information, but generally you have to search online for the full user manual.
I once talked to an engineer at a major UK CNC factory who was trying to figure out how to make sense of the data being emitted from his Siemens SINUMERIK device (he wanted to use the sensor data for predictive maintenance). The reference manual was simply too dense and too cryptic for him to parse, because manuals are written for completeness, not searchability. He ended up having to manually change each setting and see how the data changed when the machine was operating.
This is not an efficient use of engineering time.
If OEMs added on-device RAG to their HMIs, they could stand out in a crowded market. The easier a machine is to use and fix, the more likely customers are to stick with it and tell others to do the same.
A real-life example: SECO’s on-device RAG prototype
Many technology companies are already experimenting with the scenario I just described.
At Embedded World 2025, Italian embedded systems company SECO demonstrated an AI assistant running entirely on a Qualcomm Dragonwing system-on-module. The setup ran two workloads: a chat interface using Llama 3.2 3B, and a RAG pipeline retrieving from local document collections. No cloud involved. Their engineers achieved 10.3 tokens per second using llama.cpp and Qualcomm’s AI Engine SDK to distribute work across CPU, GPU, and NPU cores.

Source: “SECO’s AI assistant integrates RAG with LLM on edge AI device”
This project proves that hardware vendors are designing new modules with AI workloads in mind from the start. SECO managed to get a 4B parameter model, quantized to 4 bits, to run at useful speeds on hardware that’s already deployed in millions of machines. SECO is now evaluating these chipsets for industrial automation, medical devices, and their modular vision HMI family.
Could this prototype run on the hardware in the average CNC machine today?
The short answer is probably not. SECO’s demo works because they designed a purpose-built board for it. The Qualcomm Dragonwing platform combines CPU, GPU, and NPU cores specifically optimized for AI workloads. That’s what it takes to run a 3B parameter model at useful speeds.
But AI-optimized silicon adds cost. For OEMs designing the next generation of CNC controllers or HMIs, every dollar on the bill of materials matters. If adding on-device RAG means speccing expensive boards with dedicated neural accelerators, the feature becomes hard to justify for mid-range products.
Fine-tuned smaller models change that equation. A 1B parameter model that’s been distilled for your specific documentation runs on commodity CPUs with 4-8GB of RAM. That’s hardware OEMs are already putting in their controllers so the incremental cost of adding RAG is much lower.
But of course, there’s a trade-off when you go down to 1B parameters or lower. The models begin to struggle with the nuanced reasoning that RAG requires. But you can mitigate for this by fine-tuning them on your domain.
Common Issues with small base models
When you try to do RAG with base models around 1B parameters or lower, they begin to exhibit specific unwanted behaviors such as:
-
Retrieval noise amplification. In real RAG systems, the retrieval step returns 3-4 candidate chunks ranked by relevance. Only the top one might contain the correct answer. Larger models can sift through this noise and extract what matters. Smaller base models often get confused by the distractors and produce garbled or incorrect answers.
-
Format and structure sensitivity. Industrial documentation is dense with signal paths (like DB10.DBX1.0), parameter codes (like MD11320), and nested table structures. Smaller base models frequently hallucinate parameter numbers or misattribute values from adjacent rows.
-
Instruction following. When you need the model to return structured output (say, a JSON object with specific fields) smaller base models are more likely to drift off-format or include extraneous explanation.
Fine-tuning closes the quality gap
This is where fine-tuning becomes essential for getting the most out of the SLM. By distilling knowledge from a larger teacher model into a smaller student, we can recover most of the accuracy lost to model compression.
In our tests with a Llama 1B model, fine-tuning improved accuracy from 45.1% to 61.1%—a +16 percentage point improvement that brings it to parity with a Llama 3B base model (60.4%). In other words, fine-tuning a 1B model lets it match the performance of a base model 3x its size. If your hardware can only support 1B parameters, fine-tuning is what makes that 1B model viable.
- Premium option: AI-optimized boards (GPU/NPU) + 3B base model
- Cost-effective option: Commodity CPU + smaller fine-tuned model
Both paths get you working RAG. The second one fits the bill of materials for mid-range products.
With platforms like distil labs, the fine-tuning step that used to take weeks now takes hours. All you need is your documentation structured in a specific format and a clear task definition.
So what exactly is the degree of improvement you can get by fine-tuning an SLM for RAG?
Let’s look at a concrete example.
Fine-Tuning an SLM for RAG using distil labs
Our hypothesis is that a fine-tuned SLM should outperform a base model at the RAG task of extracting accurate answers from retrieved documentation chunks. We tested this with real industrial documentation. We took a user manual for a Siemens SIMATIC S7-1200 Programmable controller and fine-tuned a Llama 1B model to more accurately answer questions about the device when provided with relevant context.
The question we wanted to answer: can fine-tuning a 1B model close the gap to a 3B base model, so that OEMs don’t need expensive AI-optimized hardware?
Evaluation Results
We evaluated three models on 144 questions from the S7-1200 documentation using an LLM-as-a-Judge binary score (correct/incorrect):
| Model | Accuracy | Correct / Total |
|---|---|---|
| Llama 3B Base | 60.4% | 87 / 144 |
| Llama 1B Base (no fine-tuning) | 45.1% | 65 / 144 |
| Llama 1B Tuned (after distillation) | 61.1% | 88 / 144 |
The fine-tuned model is available on HuggingFace.
We explain the LLM-as-a-Judge methodology in our RAG tutorial, but essentially, we use a capable LLM (such as gpt-oss-120b) to evaluate whether the student model’s answer correctly captures the key information from a reference answer. Here’s the prompt we give to the judge:
{
"llm_as_a_judge_instructions": "Evaluate whether the predicted answer correctly answers the question. Output 'good' if the predicted answer contains the key information from the reference answer, even if it includes additional relevant details or uses different phrasing. Only output 'bad' if the answer is factually incorrect, missing critical information, or fails to answer the question."
}The results tell a clear story: fine-tuning the 1B model improved accuracy by +16 percentage points (from 45.1% to 61.1%), bringing it to parity with the 3x-larger 3B base model. The breakdown across question categories makes the improvement even clearer:
| Category | Description | Count |
|---|---|---|
| 1 | 3B correct, 1B base wrong, 1B tuned correct (fine-tuning closes the size gap) | 22 |
| 2 | 1B base correct AND 1B tuned correct (baseline knowledge preserved) | 60 |
| 3 | 3B wrong AND 1B base wrong, 1B tuned correct (tuned 1B beats the 3B) | 6 |
In 22 cases, fine-tuning recovered answers that only the 3B model could handle before. In 6 cases, the fine-tuned 1B model outperformed both the 1B base and the 3B base—the strongest evidence that task-specific fine-tuning can outperform a model 3x its size on specialized industrial documentation.
This is the core value proposition for OEMs: a 1B model fine-tuned on your documentation can match or even beat a 3B base model, while running on hardware that costs a fraction of the price.
But scores alone are still a little abstract. Let’s look at real examples from the evaluation. These are actual model outputs, not fabricated illustrations.
Query 1: Error code interpretation
“What does error code 8181 mean for MB_COMM_LOAD?”
-
1B Base: “The error code 8181 typically represents a timeout error, where the CPU has exceeded the maximum allowed time to complete a specific task.” ❌
-
1B Tuned: “Error code 8181 indicates an invalid baud rate value for MB_COMM_LOAD.” ✅
-
3B Base: “Invalid baud rate value.” ✅
The base 1B model confidently hallucinated a plausible-sounding but wrong answer. The fine-tuned model nailed it.
Query 2: Default configuration
“What is the default IP address of the S7-1200?”
-
1B Base: “192.168.2.1” ❌
-
1B Tuned: “The CPU does not have a pre‑configured IP address; it must be manually assigned.” ✅
-
3B Base: “The context provided does not mention the default IP address of the S7-1200.” ❌
This is a Category 3 example—where the fine-tuned 1B outperforms both base models. The 1B base hallucinated a common router IP. The 3B hedged unhelpfully. Only the fine-tuned model gave the correct answer.
Query 3: Startup behavior
“How does the ‘Startup’ OB (OB 100) function?”
-
1B Base: “The Startup OB (OB 100) is responsible for executing a set of tasks that are required to initialize the system and prepare it for operation. This includes tasks such as powering up the system, initializing the memory, and setting up the operating parameters…” ❌ (vague, generic)
-
1B Tuned: “The ‘Startup’ OB (OB 100) is executed only once, at the moment the CPU changes from STOP to RUN. It performs the following actions: it is called automatically by the CPU when the operating mode changes, it runs once only, and after its execution it starts the main ‘Program cycle’ OB.” ✅
-
3B Base: “The ‘Startup’ OB (OB 100) executes one time when the operating mode of the CPU changes from STOP to RUN, including powering up in the RUN mode.” ❌ (incomplete)
Another Category 3 case. The fine-tuned 1B model provides the most complete and precise answer of all three.
The fine-tuning workflow
After seeing this improvement in accuracy, you might be wondering how to get the same results on your documentation. Let’s look at the process we went through to fine-tune the base model. Most of the work is in data preparation, but even that busywork can be accelerated using frontier LLMs.
Data preparation
Since most manuals come in PDF form, you first need to convert it to raw text. Try and preserve the document structure as much as possible. Tables, headers, and signal definitions all need to be readable.
You can do this easily with Python libraries such as pdfplumber or camelot. You can also use free desktop applications such as PDFGear.
After that, you’ll need to provide a training set, a test set and optionally some unstructured context data. You can find more details about the data preparation requirements in the article “Open Book QA for RAG data preparation”.
Using an open-source LLM to generate initial input data
You can use any capable LLM to help with data preparation. The main consideration is choosing one that won’t create licensing headaches down the road.
I used gpt-oss-120b via Groq, an open-weight model whose license permits commercial use of outputs (which includes outputs for training other models). If you’re building something you plan to deploy commercially, it’s worth checking the terms of service for whatever model you use in your data preparation pipeline.
The main constraint with gpt-oss-120b is its 130K token context window. The raw PLC manual runs to around 500K tokens, so I couldn’t process it in one shot. But most of that bulk was noise anyway.
Step 1: Clean before you generate. In my first extraction attempt, nearly 65% of the content was low-quality filler—tables of contents, alphabetical indexes, repetitive boilerplate, and chunks where less than half the characters were actually alphanumeric (think page headers, footers, and formatting artifacts). Filtering for chunks with >50% alphanumeric content reduced the dataset from 4,259 chunks to 1,493.
Step 2: Process by section. Even after cleaning, the manual was still larger than the context window. I split it into major sections (installation, configuration, diagnostics, programming interface) and processed each separately. This actually improved the output quality: the model could focus on one coherent topic at a time rather than jumping between unrelated content.
Step 3: Generate diverse Q&A pairs. For each section, I prompted gpt-oss-120b to generate realistic operator questions and their answers. The key is ensuring coverage across question types: alarm interpretation, signal identification, configuration procedures, troubleshooting steps. You want your training data to reflect the kinds of questions operators actually ask, not just what’s easy to extract from headers.
Here’s the input data I ended up with:
- Training set: ~200 Q&A pairs covering different documentation sections
- Test set: ~50 held-out pairs for evaluation
- Unstructured context: JSON containing relevant passages for each question
The unstructured context dataset guides the teacher model during synthetic data generation, helping it produce diverse, domain-specific examples. Since I was generating in batches anyway, I produced the context JSON section by section, which naturally gave good coverage across the manual.
In the end, you should end up with human-readable contexts that look like this:
{"context":"## A.17.2 CSM 1277 compact switch module\nThe CSM1277 is an Industrial Ethernet compact switch module. It can be used to multiply the Ethernet interface of the S7-1200 to allow simultaneous communication with operator panels, programming devices, or other controllers."}Here’s an example of what a training pair should look like:
{
"question": "What is the maximum number of connections for the S7-1200 CPU?",
"answer": "The S7-1200 supports a specific number of connections based on type (e.g., 8 OUC, 3 Server, 8 Client, etc.).",
"context": "10.1 Number of asynchronous communication connections supported... The CPU supports the following maximum number... 8 connections for Open User Communications..."
}Configuring the training job
With the data prepared, I configured the distillation job. The configuration has two main sections: the base settings (which models to use) and the synthetic data generation settings.
base:
task: question-answering-open-book
student_model_name: Llama-3.2-1B-Instruct
teacher_model_name: deepseek.v3.1
synthgen:
mutation_topics:
- "technical specifications, limits, and maximum/minimum values"
- "step-by-step configuration and setup procedures"
- "the purpose and function of specific instructions or parameters"
- "what happens when a condition occurs or a parameter changes"
- "error indicators, diagnostics, and troubleshooting"
- "differences between similar components or settings"
- "data types, memory usage, and addressing"
- "default values and behavior when no configuration is specified"
- "practical use cases and real-world examples"
- "safety precautions and hardware warnings"The base configuration is straightforward: we’re doing open-book question answering (RAG), using Llama 1B as the student and DeepSeek V3.1 as the teacher. The interesting part is mutation_topics.
Why mutation topics matter
During distillation, the platform generates thousands of synthetic Q&A pairs beyond your initial seed examples. This is what allows you to start with just 200 hand-crafted examples and end up with enough training data to fine-tune a model effectively.
The problem is that without guidance, synthetic data generation tends to produce repetitive questions. The teacher model will generate whatever’s easiest to extract from the documentation. These might be definitional questions like “What is the S7-1200?” or “What does PLC stand for?” These are valid questions, but they don’t reflect how operators actually query documentation under pressure.
Real operator questions are more varied. When I analyzed my test set, the question patterns broke down like this:
- “What is the…” (46%) — specifications, definitions, purposes
- “How do you…” (25%) — procedures, configuration steps
- “What does the…” (10%) — function and behavior explanations
- “What happens if…” (8%) — consequences and edge cases
Mutation topics address this by steering synthetic data generation. For each synthetic example, the platform samples one mutation topic and includes it in the prompt to the teacher model: “Generated examples should focus on {mutation}.” This ensures the training data covers the full spectrum of question types—not just the easy ones.
The mutation topics I used were derived from analyzing what kinds of questions appear in real documentation queries:
| Mutation Topic | What It Generates |
|---|---|
| Technical specifications, limits, and maximum/minimum values | ”What is the maximum number of connections?” |
| Step-by-step configuration and setup procedures | ”How do I configure the handwheel resolution?” |
| What happens when a condition occurs or a parameter changes | ”What happens if ManualEnable is set to TRUE?” |
| Error indicators, diagnostics, and troubleshooting | ”What does alarm 4571 mean?” |
| Differences between similar components or settings | ”What’s the difference between JOG and MDI mode?” |
| Default values and behavior when no configuration is specified | ”What is the default timeout value?” |
| Practical use cases and real-world examples | ”When would I use a high-speed counter?” |
| Safety precautions and hardware warnings | ”What precautions are needed when hot-swapping modules?” |
For effective distillation, you need clean data and diverse mutations
Getting good results from distillation required both pieces working together:
-
Clean unstructured data — Filtering out the junk (tables of contents, indexes, formatting artifacts) meant the teacher model was working with actual documentation content, not noise.
-
Diverse mutation topics — Steering synthetic generation toward different question types meant the student model learned to handle the full range of queries operators actually ask.
In my initial attempts, we skipped both of these steps and got mediocre results—the fine-tuned model barely outperformed the base model. After cleaning the data and adding mutation topics, the improvement was dramatic: from 45.1% to 61.1% accuracy on 144 test questions, bringing the 1B model to parity with the 3B base.
Distillation isn’t going to magically produce the perfect model on the first attempt. The quality of your synthetic data matters enormously, and that quality comes from both the source material (clean documentation) and the generation process (diverse question types).
Once we identified the right mutation topics, we were able to get the results that we introduced at the start of this section—a fine-tuned 1B model that matches or beats a 3B base model on domain-specific documentation questions.
Beyond the HMI: RAG on a phone or tablet
So far we’ve focused on a future scenario where OEMs embed RAG into machine HMIs. But what about right now? The simple solution is to run a fine-tuned small model directly on a phone or tablet.
A 1B model quantised to 4-bit is about 500MB. That’s trivial for modern devices. With frameworks like llama.cpp or ExecuTorch, plus a lightweight vector store, you’ve got a fully offline RAG system in your pocket.
As we’ve mebtioned, this is very useful in air-gapped plants, substations, rigs and patchy factory floors. if you have the model and the docs preloaded on a handheld device, you dont need to tunnel through a VPN to access the cloud
Even today, OEMs could build companion RAG reference apps for their machines (or you could build one yourself if you’re feeling adventurous). You’d just need to download it once, use it anywhere, and pull any updates when you have connectivity. Far more realistic than assuming perfect connectivity on site.
This would be very handy for service technicians who move between sites. Rather than carrying binders of documentation or relying on intermittent VPN access to a knowledge base, they carry a single device that can answer questions about any machine they’re certified to work on.
Fine-tuned SLMs can enable OEMs to provide better on-device support
When it comes to finding the right technical information, the problem usually isn’t that the information is missing. Rather, it’s hidden inside 1,200-page PDFs that nobody has time to search when production is down.
RAG is changing the way humans find information. And fine-tuning SLMs can make RAG work on the factory floor, where it’s most needed.
The experiment we ran here took a dense PLC manual, cleaned out the noise, generated diverse training data, and produced a 1B model that matches a 3B base model. That fine-tuned model runs on a CPU (including a phone’s CPU). Which means you dont have to depend on internet connectivity.
Hardware vendors like SECO are building AI-ready modules with dedicated GPU and NPU cores. That hardware works, but it adds cost for manufacturers (and is only in prototype stage). Fine-tuned smaller models let you skip the expensive silicon. A 1B model that’s been distilled for your specific documentation runs on commodity CPUs, which means on-device RAG becomes viable at price points that make sense for volume deployments—whether that’s embedded in the machine’s HMI or running on a technician’s tablet in the field.
OEMs have a real opportunity here. We often say documentation is a differentiator, yet most manuals still end up in a drawer or stuck on a USB stick never to be read. On-device RAG changes the dynamic. When the information lives on the machine panel or in a technician’s pocket, it becomes a working tool that supports decisions in real time. Over time, that kind of access builds trust with the people who operate and maintain the equipment.