Full-Stack Production Language Models: Expert Model Optimization Meets Scalable GPU Infrastructure
Distil Labs is the developer platform for building custom small language models. Companies train SLMs within hours to replace expensive large models, leading to dramatically lower inference costs & latency – while preserving accuracy. Any mid-size frontier LLM (Gemini Flash Lite, GPT mini, Grok Fast, …), can reliably be replaced with small models customized to that specific task.
Cerebrium is the serverless GPU infrastructure platform that powers Distil Labs' production workloads. Together, the two companies form a complete ML stack: Distil Labs brings deep model optimization expertise—fine-tuning, distillation, and prompt engineering while Cerebrium provides the elastic, globally distributed compute layer that makes it all run at scale.
The result is an end-to-end offering for any company looking to move from bloated, expensive LLM inference to lean, production-grade small-model deployments, without building or managing either the ML pipeline or the infrastructure themselves.
How the Stack Comes Together
.png)
Distil Labs owns the model layer. Their platform fine-tunes, distills, and optimizes models for each customer's specific task—delivering accuracy improvements that often exceed the original large model while dramatically reducing parameter count and compute requirements.
Cerebrium owns the infrastructure layer. Their serverless GPU platform provides granular deployment controls, limitless international autoscaling, optimized latency, and competitive on-demand pricing—all without requiring Distil Labs to manage a single GPU.
Why Infrastructure Matters
Distil Labs' customers run workloads that fluctuate from low, steady traffic to bursts reaching hundreds of requests per second. That demand profile requires infrastructure that can scale from zero to high concurrency quickly, support fully custom model weights and API definitions across multiple concurrent deployments, provide access to a broad array of GPU types, and deliver fast cold starts alongside competitive pricing.
Building and managing this kind of hyperscale-grade GPU infrastructure internally would have pulled the Distil Labs engineering team away from their core differentiator: making models smaller, faster, and more accurate. Instead, the team partnered with Cerebrium to handle the compute layer entirely—freeing Distil Labs to focus on the ML work that drives customer outcomes.
What Customers Get
The combined Distil Labs + Cerebrium stack delivers measurable, production-grade results:
Performance at Scale
Distil Labs runs hundreds of requests per second per model during high-traffic periods, with multiple models deployed concurrently. Autoscaling ensures smooth handling of traffic spikes and production-grade stability. Upcoming GPU memory snapshot improvements promise even faster cold starts, further strengthening performance under bursty demand.
Customer Impact
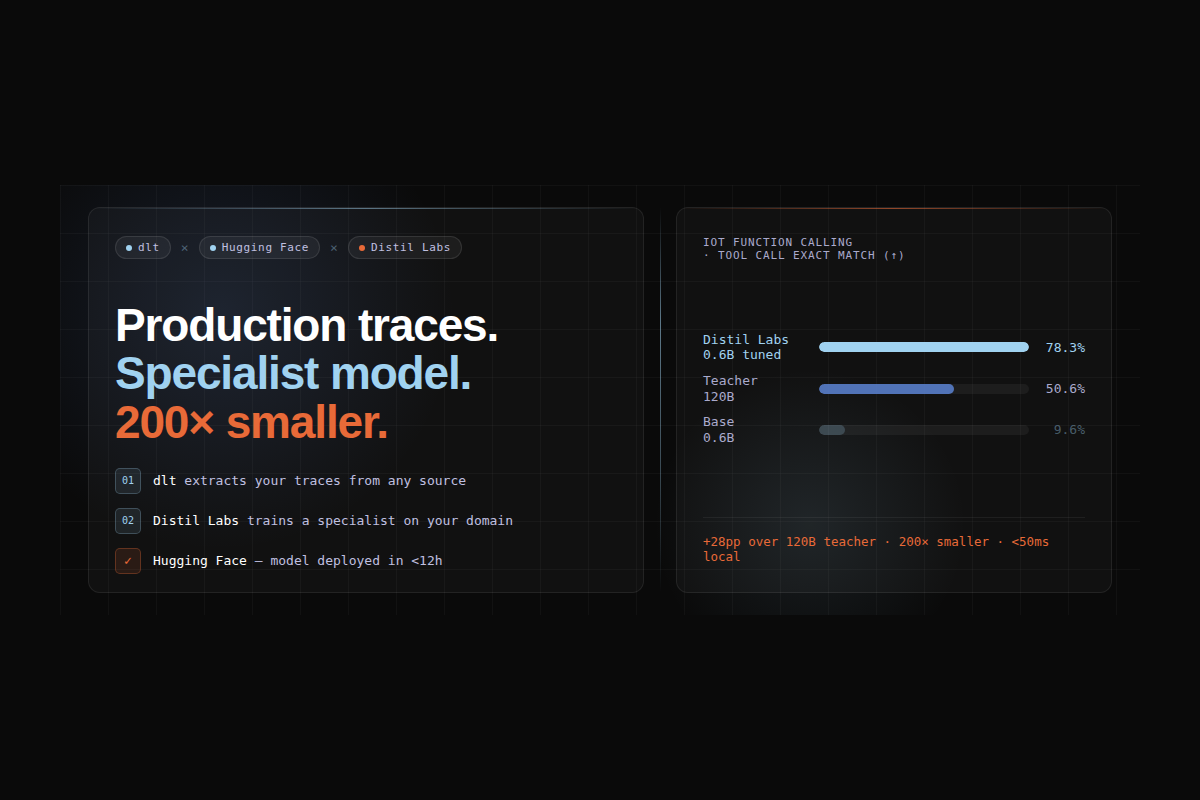
One customer was running single-digit millions of requests per day with approximately one-second p99 latency. By combining Distil Labs' model optimization with Cerebrium's infrastructure, the customer saw inference costs drop by 50%, accuracy improve by 10 percentage points compared to a mid-sized frontier model, and latency drop all while keeping reliability consistent at production scale.
Faster Iteration
Because neither the ML engineering nor the infrastructure management falls on the end customer, development cycles shorten materially. Companies can go from prototype to production-grade small-model inference without hiring specialized teams for either layer.
Get Started
Most companies building with LLMs today are overpaying for inference, over-provisioning infrastructure, or both. The Distil Labs + Cerebrium stack eliminates that trade-off: you get models that are smaller, faster, and more accurate, running on infrastructure that scales precisely to your workload.
If you have a task currently handled by a frontier LLM and want to explore what a custom small model on serverless GPUs could look like, reach out to either team:
- Distil Labs: distillabs.ai | Train task-specific small models that match or exceed LLM accuracy
- Cerebrium: cerebrium.ai | Deploy on serverless GPUs with autoscaling, global reach, and zero infrastructure overhead