1) Introduction
Large language models changed the way we build AI products but they are not suited for all applications and environments. In security, fintech, robotics, and defense, developers are often stuck between strict privacy rules, tight latency budgets, and limited compute. Small language models (SLMs) solve all of those problems, but out-of-the-box accuracy rarely clears the production bar. That’s where the distil labs platform comes in.
distil labs turns a prompt and a few dozen examples into a small accurate expert agent. Our platform automates data generation, curation, fine-tuning, and evaluation so you can reach LLM-level results with models 50-400x smaller, deployable almost anywhere, in hours. Our north star: slash time-to-agent.
In this post we’ll give you a high-level overview of how to create high-quality SLMs without breaking the bank, explain how our platform works, go through a detailed example and show performance on an example use-case. You’ll see that, counterintuitively, fine-tuned small models can not just match, but exceed, the performance of LLMs on specific tasks. If you want to dive into the numbers, our next post focuses on benchmarking.
2) How it works
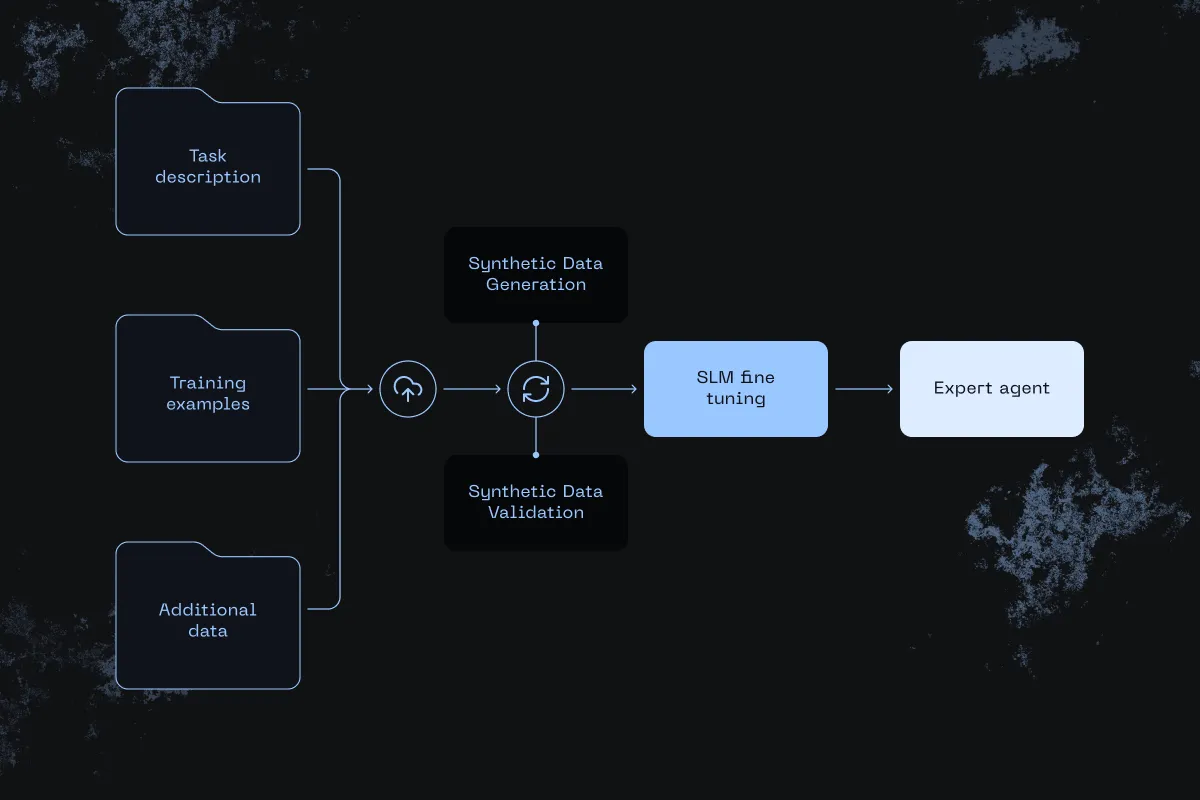
distil labs orchestrates an end-to-end loop: you supply a lightweight task description and few training examples as inputs; we generate and validate in-domain synthetic data to fill the gaps, and fine-tune a compact student that emulates the teacher on your task. The result is a deployment-ready small agent packaged for your target runtime.
Inputs
To tune an SLM, you need to provide three inputs:
- Task description (a plain-English definition; your existing LLM prompt is a good start).
- Small train & test sets — 20-100 labeled examples are usually enough. Harder problems may require more, though still orders of magnitude less labelled data than conventional fine-tuning.
- Additional data (docs, logs, tickets) to guide the generation towards your domain.
In case the teacher model cannot solve your task well, you can iterate on both the inputs you provide as well as the teacher model used. While a tuned student model can outperform the teacher, the teacher needs to be able to solve the task at least somewhat for the whole process to work.
Data generation
We run an iterative two-stage loop - generate -> validate -> repeat — until coverage is good:
- Generate new examples asking the teacher LLM to create realistic synthetic inputs and outputs for a given task. The teacher LLM is prompted with the problem description, a rotating sample of seed examples, and (optionally) a randomly selected unstructured document to stay on-domain.
- Validate, removing low-quality items using a set of validators. Each task has a specific list, such as dropping examples that are too short/long or start with non-alphanumeric junk, de-duplicating (using metrics like METEOR & ROUGE), or excluding samples not adhering to the pre-defined input/output schemas. We also make sure that synthetic data matches the distribution of training data (e.g. in class distribution).
Each supported task (e.g., classification, information extraction, QA, tool-use) follows the same overall loop but uses a task-specific workflow - especially for data-generation prompts and validation criteria.
Model training
Using the curated dataset, we fine-tune a compact student model with a method inspired by knowledge distillation [Hinton et al, 2015] which transfers the domain-specific knowledge from the large teacher to a small student. At the end of training, the student learns to emulate the teacher’s domain behavior while retaining a small footprint, enabling private/on-premises deployment out of the box.
3) Example use-case: PII redaction
We tackle policy-aware PII (Personally Identifiable Information) redaction for support emails and tickets - a task where privacy isn’t negotiable and data may not leave the customer’s perimeter. Cloud LLMs are not an option due to compliance concerns, so instead we train a small language model (SLM), which runs locally on CPUs ensuring sensitive text never crosses the boundary.
In this use case, the student model learns to detect entities and apply policy logic (e.g. redact patient names and full card numbers while keeping clinicians and last-4) with verifiably consistent behavior. With only a few dozen examples, we reach production-grade policy compliance and eliminate the privacy and integration risks of cloud inference, aligning perfectly with teams that need automation on their own hardware.
The input to our platform for this task
Produce a redacted version of customer/support texts, removing sensitive personal data while preserving operational signals (order IDs, last-4 of cards, clinician names). The model must return:
redacted_textwith minimal substitutions (e.g.,[PERSON],[CARD_LAST4:####])- an
entitiesarray that lists every redacted token, each with{value: original_value, replacement_token: replacement}.
Redact (replace in text):
- PERSON (customer/patient names) ->
[PERSON] - EMAIL ->
[EMAIL] - PHONE (any international format) ->
[PHONE] - ADDRESS (street + number, or full postal lines) ->
[ADDRESS] - SSN / National ID / MRN ->
[SSN]/[ID]/[MRN] - CREDIT_CARD (full 13-19 digit number, with spaces/hyphens) ->
[CARD_LAST4:####](keep last-4 only) - IBAN / Bank account ->
[IBAN_LAST4:####](keep last-4 only)
Keep (do not redact):
- Clinician/doctor names when clearly marked by a medical title (e.g.,
Dr.,MD,DO,RN). - Card last-4 when referenced as last-4 only (“ending 9021”, ”•••• 9021”).
- Operational IDs: order/ticket/invoice numbers, device serials, case IDs.
- Non-personal org info: company names, product names, team names.
Example data:
{
"input":"Please verify account with SSN 987654321 and send update to alex@x.io.",
"output": {
"redacted_text":"Please verify account with SSN [SSN] and send update to [EMAIL].",
"entities":[
{"replacement_token":"[SSN]","value":"987654321"},
{"replacement_token":"[EMAIL]","value":"alex@x.io"}
]
}
}Distillation Pipeline
Synthesize domain documents. From your seed examples and optional unstructured corpus, the teacher generates realistic source texts — mirroring tone, jargon, and edge cases in your domain. Prompts stay “on-rails” via the task description and a rotating sample of seed/context.
Generate labeled extractions. For each (real or synthetic) document, the teacher produces the target JSON-like object schema, yielding (document, structured-label) pairs for training.
Validate. We validate length, format, filter based on mutual similarity as well as schema checks (presence of required fields present, disallowing any extra keys.
Train & evaluate. We fine-tune the student on curated (document -> schema) pairs, then evaluate on your held-out test set.
Results
We started with 50 seed examples (balanced across policy cases) split between test and train. In this case, we compare the teacher (LLama3.3 70B) evaluated with *k-*shot examples drawn only from the training split and the trained student (Llama3.2 3B) trained on seed + curated synthetic data. For reference we also include the student model trained only on the seed data (Seed Student) and the performance of the untrained model with k-shot prompting (Base Student). In terms of metrics for PII redaction we report LLM-as-a-Judge that compares the predicted JSON to the reference answer based on the task description. We compare the teacher model, the untrained student and the trained student which is the result of the distillation process.
| Dataset | Teacher (^) | Trained Student (^) | Base Student (^) | Seed Student (^) |
|---|---|---|---|---|
| PII Redaction | 0.85 +/- 0.01 | 0.87 +/- 0.01 | 0.54 +/- 0.03 | 0.73 +/- 0.01 |
Looking at the results, we see the trained SLM vastly outperforms the baseline model as well as the cloud-hosted LLM. This is quite a feat: we have outperformed the teacher performance using a model 25x smaller! Going by prices of major model inference provider this gives you 150x decrease in price! You might be asking how the teacher LLM can train a model better than itself - the main reason is the introduction of additional signal through the data validators and behaviour similar to LLM Self-Improvement; that a topic for the next blogpost however.
5) Conclusion
distil labs turns a prompt and 20 seed examples into a production-ready small expert agent. Our distilled students consistently match strong cloud LLMs while being up to 50x smaller - delivering private, low-latency inference on your own hardware. The key is our task-specific workflows: iterative, data generation with strict validators, followed by fine-tuning and rigorous evaluation.
The result is shorter time-to-agent and deployment flexibility - from on-premises CPUs to edge GPUs - without compromising accuracy. If you have a task in mind, start with a short description and a handful of examples; we’ll take it from there. Use the link at the top to sign up and start straight away!