
When was the last time you screamed at a chatbot in all caps?
“THE OUTPUT MUST BE IN JSON FORMAT”.
“YOU ABSOLUTELY MUST QUERY THE VECTOR DATABASE”.
“IF YOU DON’T KNOW THE ANSWER, DON’T MAKE IT UP”.
If any of these sound familiar, you probably need to be using a fine-tuned model. That’s because prompt engineering with general-purpose language models can only get you so far. Fine-tuned language models are more effective than general-purpose models in performing specific downstream tasks, such as tool calling (in agentic applications), classification, or information extraction, because they have been explicitly trained to do so.
The problem is that fine-tuning language models, whether large or small, requires robust datasets, complex distributed training pipelines, and ample compute resources. Furthermore, fine-tuned large language models are still… large, making them difficult and expensive to deploy. Small language models (SLMs), on the other hand, have significantly lower inference costs, lower latency, and are optimized for deployment on edge devices and use in agentic workflows.
And now you can fine-tune a SLM with just a prompt. In this post, we introduce vibe-tuning, a bleeding-edge technique that allows you to fine-tune open source models with natural language.
In addition to introducing and explaining vibe-tuning, this piece will cover the limitations of prompt engineering, the challenges of traditional fine-tuning, the role of knowledge distillation in vibe-tuning, and how to vibe-tune a SLM for intent classification with just a prompt using the distil labs platform.
When Prompt Engineering Isn’t Enough
Screaming at language models is no fun. Neither is spending an entire day perfecting a prompt only to have it produce inconsistent results the next day. In use cases where accuracy, tone, and response format aren’t paramount, such as prototypes or proofs-of-concept, prompt engineering may deliver “good enough” results. However, relying solely on prompt engineering techniques is often insufficient for production-grade models and applications.
Limitations of Prompt Engineering
Prompt engineering is an inference-time technique that guides the model’s existing knowledge through carefully designing, structuring, and phrasing the model prompt. This means that it cannot adjust the model weights to introduce new knowledge that the model has not already been trained on.
A recent study on prompt engineering found that anticipating the impact of a specific prompting technique on a model’s output is difficult, which should come as no surprise to prompt engineers and chatbot users. The study also found that “being polite” to a language model can either improve responses or make them worse. Essentially, prompt engineering yields inconsistent and unpredictable results.
Paradoxically, language models are increasingly being accused of being “too polite” to users. This recent phenomenon, referred to as sycophancy, prioritizes agreement with the user over factual accuracy. Sycophancy ultimately leads to degraded performance over time and exacerbates user bias. Ultimately, when improvement gains from prompt engineering have plateaued, it’s time to turn to a more robust solution.
Fine-tuning SLMs for Domain- and Task-Specific Use Cases
General-purpose LLMs have a broad knowledge base and are trained to be good at everything. However, for specific use cases, you may prefer a model that is excellent at only a few, very specific tasks. This is where fine-tuning comes into play.
Fine-tuning is a post-training machine learning technique that encapsulates new knowledge by updating the pre-trained model’s internal weights through additional training on a specific dataset, allowing it to transfer its broad, existing knowledge and specialize in a new task or domain.
For the purposes of this article, we will focus on fine-tuning SLMs. SLMs are broadly defined as language models with 10 billion parameters or less and are optimized to run on a single piece of consumer-grade hardware.
There are several key reasons why you might want to fine-tune a SLM:
- Superior task-specific performance. Fine-tuning a SLM with a small, specific dataset improves task accuracy beyond what a general-purpose model can achieve (benchmarks).
- Better understanding of domain-specific language. Fine-tuned models are also able to better understand domain-specific language and terminology (e.g. legal, medical, financial) that may not be well-represented or understood by a generic model.
- Efficiency and cost savings with smaller models. Fine-tuned SLMs can compete with much larger models on specific tasks, while having faster response times and cheaper use in production, especially at scale.
Challenges of Fine-Tuning Small Language Models
Fine-tuning SLMs is not a simple task. This can be a long and costly undertaking with no guarantee to deliver a model with improved performance.
Some of the most common challenges of fine-tuning SLMs are:
- Sourcing quality data. Finding a high-quality dataset that’s large enough for fine-tuning can be difficult, especially when the downstream task is niche.
- Scaling training pipelines is complex. Fine-tuning generative SLMs requires a lot of spare VRAM capacity, which often leads to out-of-memory challenges, resulting in the need for distributed training frameworks, specialized engineering knowledge, and advanced model optimization techniques.
- Slow and painful iteration. Fine-tuning a performant model on the first iteration is rare. Insufficient training data, half-baked evals frameworks, debugging, and iterating on hyperparameters all eat up valuable time.
Although fine-tuning significantly improves SLM performance and efficiency for downstream tasks, the process requires robust data, highly skilled engineers, and can be incredibly time-consuming.
Introducing Vibe-Tuning: Fine-Tuning a SLM with Just a Prompt
Vibe-tuning is a technique that allows you to fine-tune a SLM with natural language. It automates synthetic data generation and the required compute setup, fine-tuning and hyperparameter optimization, and model evaluation, allowing you to fine-tune a deployable SLM in hours instead of weeks.
How is Vibe-Tuning Different from Vibe Coding?
Vibe coding, first coined by Andrej Karpathy in early 2025, is a method to generate code exclusively by prompting LLMs. Vibe-tuning builds on the concept of vibe coding, ultimately allowing you to fine-tune a SLM by prompting a LLM. There are, however, a few key differences between the two.
While vibe coding can produce verbose and brittle code (with potential security flaws), vibe-tuning produces a model that has automatically been evaluated and is ready for deployment. Furthermore, vibe coding is a simple prompt-and-response process. Vibe-tuning is built on top of a complex model distillation pipeline that allows for customisation, while abstracting away the complexity.
What is Model Distillation?
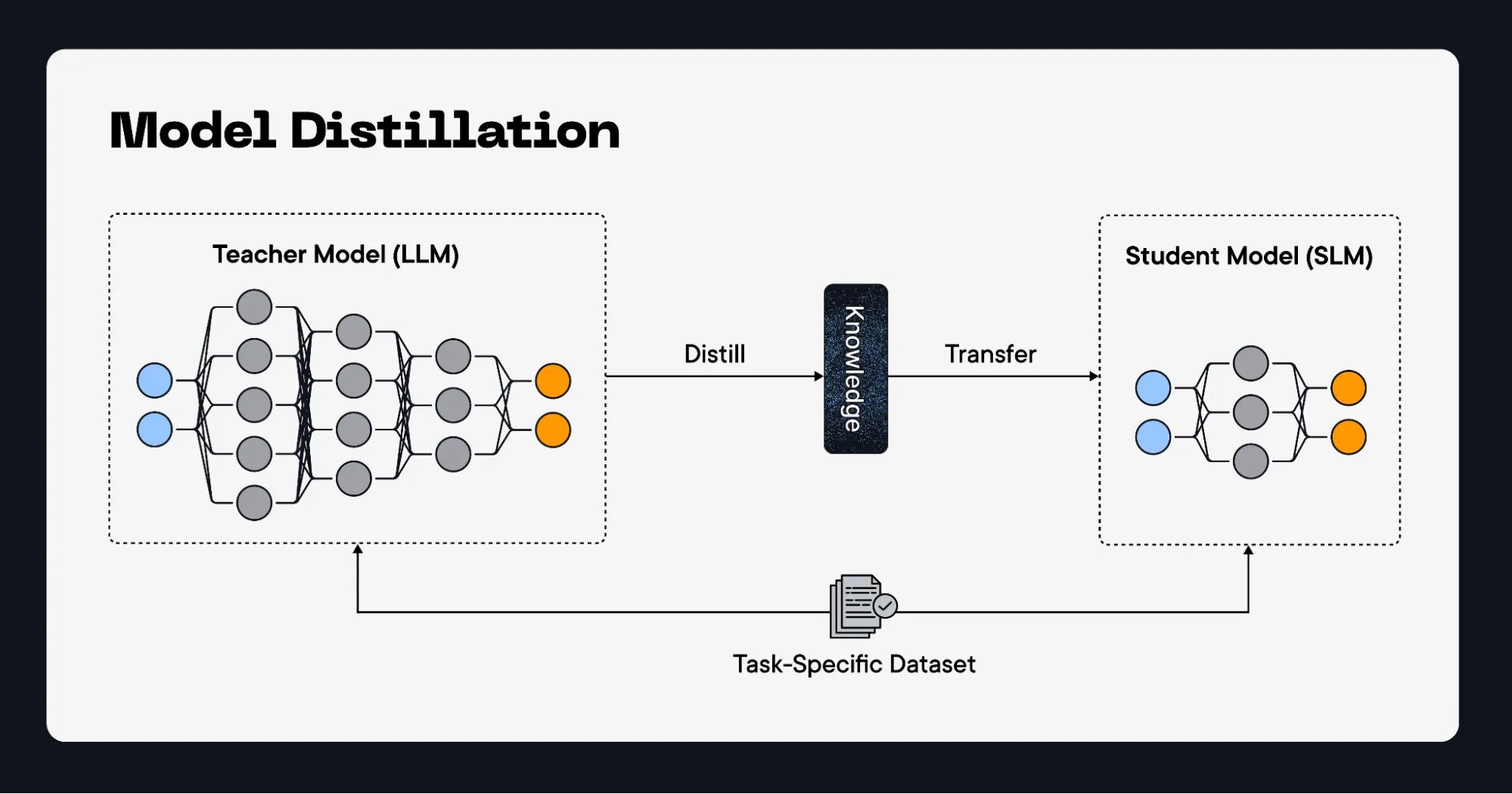
Model distillation, also referred to as knowledge distillation, is a machine learning technique that transfers a comprehensive knowledge base from a massive pre-trained large language model into a much smaller model with minimal (if any) loss in performance. SLMs boast significantly faster inference speeds, are cheaper to operate, are capable of being deployed on edge devices, and are optimized for agentic workflows. SLMs distilled from larger LLMs can even outperform their parent model on a specific task.
The main prerequisites for model distillation are the selection of a large pre-trained model (the large Teacher Model), a smaller model (the Student Model), and a focused, task-specific dataset. Here’s what happens during the distillation process:
- The Teacher model generates realistic synthetic examples appropriate for the target task to cover the depth and breadth of the problem. Generated data is curated by removing bad examples to ensure the resulting dataset is high quality, diverse, and sufficiently covers the full problem domain
- The Student Model is fine-tuned to mimic the Teacher Model’s predictions until its performance plateaus and it has minimized a combined loss function.
- The Student Model is benchmarked against the Teacher Model. Both of the models are evaluated by making predictions on the same test dataset. The resulting Student Model should be significantly smaller and maintain a comparable (possibly superior) level of performance as the Teacher Model.
How (and Why) Does Vibe-Tuning Work?
Vibe-tuning takes a prompt as input and delivers a downloadable fine-tuned small language model as an output. It is powered by a robust pipeline that automates synthetic data generation, model distillation, and model evaluation.
Successful model distillation relies on two critical pieces of input: a clear task description and labeled examples of the intended task. In vibe-tuning, both of these inputs are generated based on a single user prompt. The task description is inferred from your prompt (and reformulated, if necessary) and synthetic training examples are generated along with preliminary labels that you either accept or decline.
Alternatively, the distil labs platform allows you to write your own task description, upload your own training and test datasets, and add additional documents or unstructured data to provide additional context.
Next, you select a Teacher Model and Student Model. distil labs offers several state-of-the-art open source models to choose from (with more models arriving on a regular basis):
| Teacher Models | Student Models |
|---|---|
deepseek.r1 deepseek.v3.1 Qwen3-235B-A22B-Instruct-2507 Qwen3-480B-A35B-Coder Qwen2.5-VL-72B-Instruct Llama-3.1-405B-Instruct Llama-3.1-8B-Instruct Llama-3.1-70B-Instruct Llama-3.3-70B-Instruct openai.gpt-oss-120b openai.gpt-oss-120b-thinking | Llama-3.2-1B-Instruct Llama-3.2-3B-Instruct Llama-3.1-8B-Instruct SmolLM2-135M-Instruct gemma-3-270m-it gemma-3-1b-it Qwen3-4B-Instruct-2507 Qwen3-8B granite-3.1-8b-instruct granite-3.3-8b-instruct |
Now the distillation process is ready to begin! The entire distillation process, including infrastructure and compute setup is fully automated. For more granular control, you can also adjust specific hyperparameters by optionally uploading a custom configuration file. Developers also have the option to use distil labs API.
Once distillation is complete, the performance of the resulting Student Model is automatically evaluated and compared with the Teacher Model and is ready to be downloaded and deployed. There are several ways to access and deploy an SLM fine-tuned using distil labs:
- Download the model directly from the platform and deploy it on your machine with Ollama or vLLM.
- Deploy the model directly with distil labs.
- Upload the model to your HuggingFace account.
How to Fine-Tune a LLM for Intent Classification with a Prompt
To demonstrate how vibe-tuning works, we’ll work through a real-world use case for fine-tuning an SLM to classify the intent of user messages to a customer service chatbot.
Intent classification assigns a user’s text or speech input to a predefined category that represents their core goal or action. Accurately identifying user intent is especially critical in agentic workflows, as it serves as a core routing signal, directing the queries to the correct specialized tools or sub-agents.
Specifically, we’ll distill GPT-OSS-120B into a small language model trained to distinguish between three types of user messages: order_status, delivery_inquiry and return_inquiry. The ultimate goal of the model is to separate actionable questions (e.g. order status, return status, return policy) from inactionable questions (e.g. delivery status, delivery instructions, courier issues) that should be redirected to a third party. If deployed in an agentic workflow, this model would save significant resources in not attempting to answer inactionable questions.
Below, we’ll go over the individual steps to fine-tune a text classification model with the distil labs platform, using its interactive labeling functionality to generate a synthetic training dataset entirely from scratch.
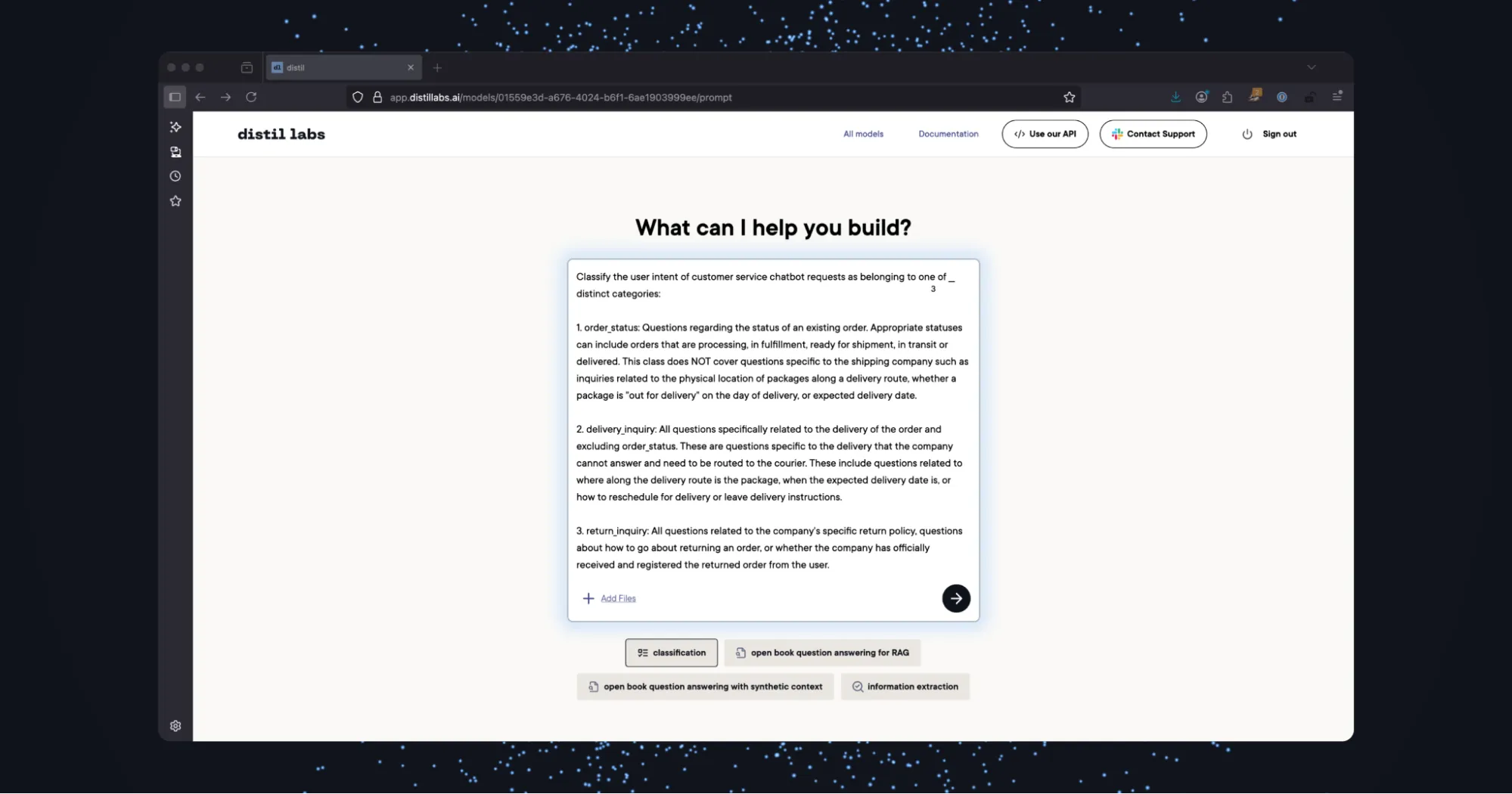
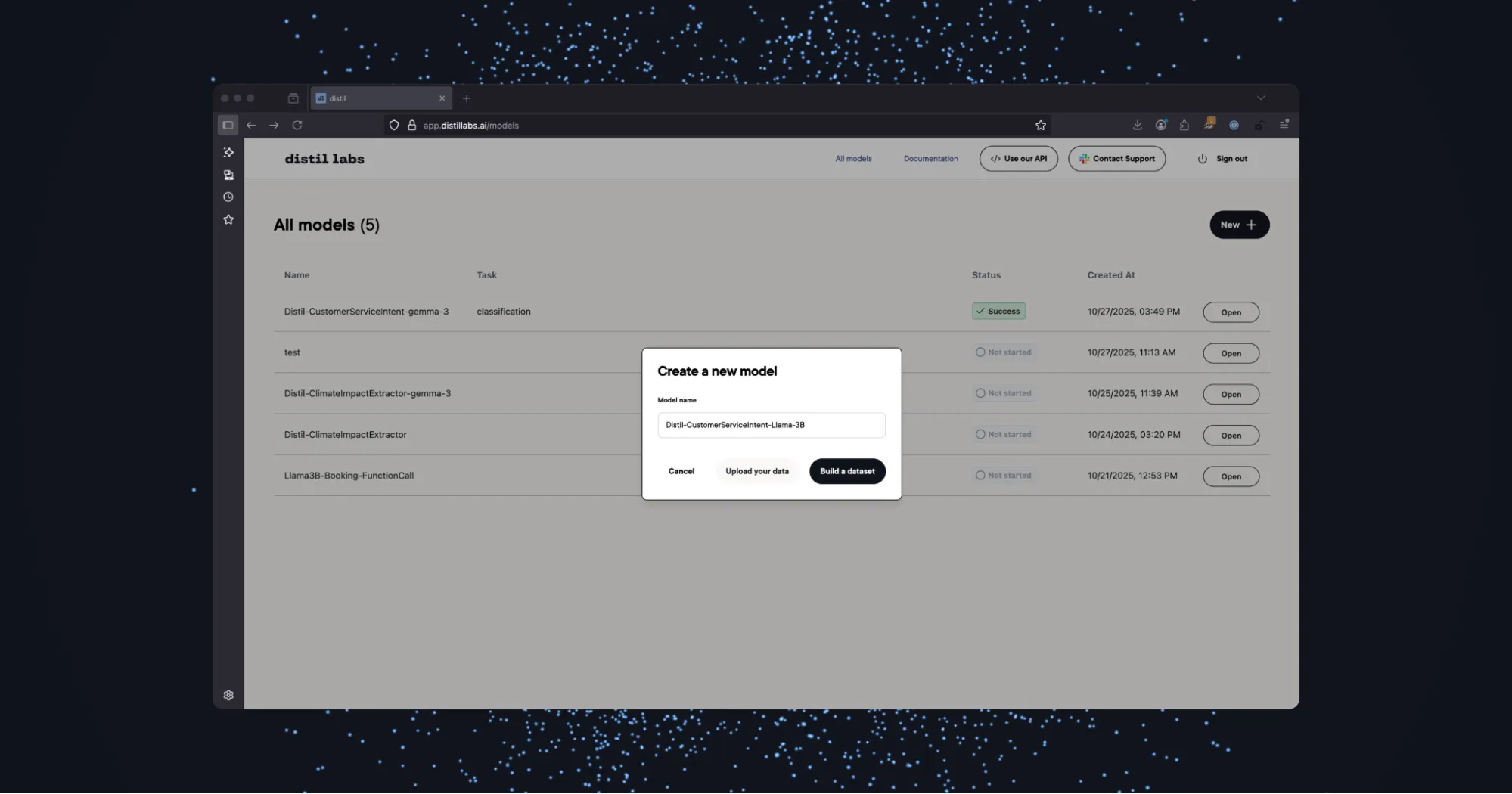
Step 1: Name the Model and Build a Synthetic Dataset.
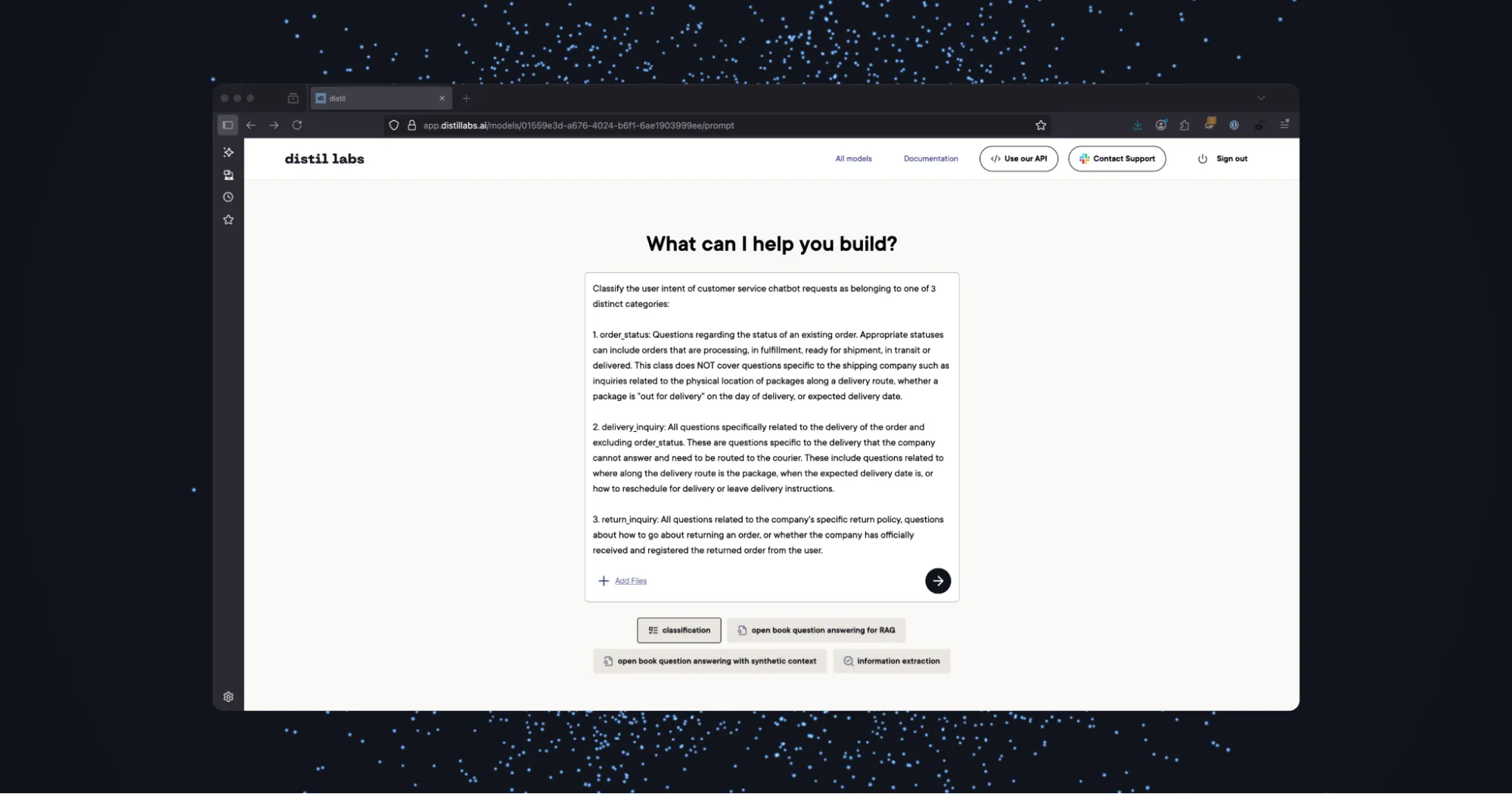
Create a new model, give it a name, and click Build a Dataset.
Select the classification button and write a descriptive prompt that includes specific names and definitions for each of the class categories.
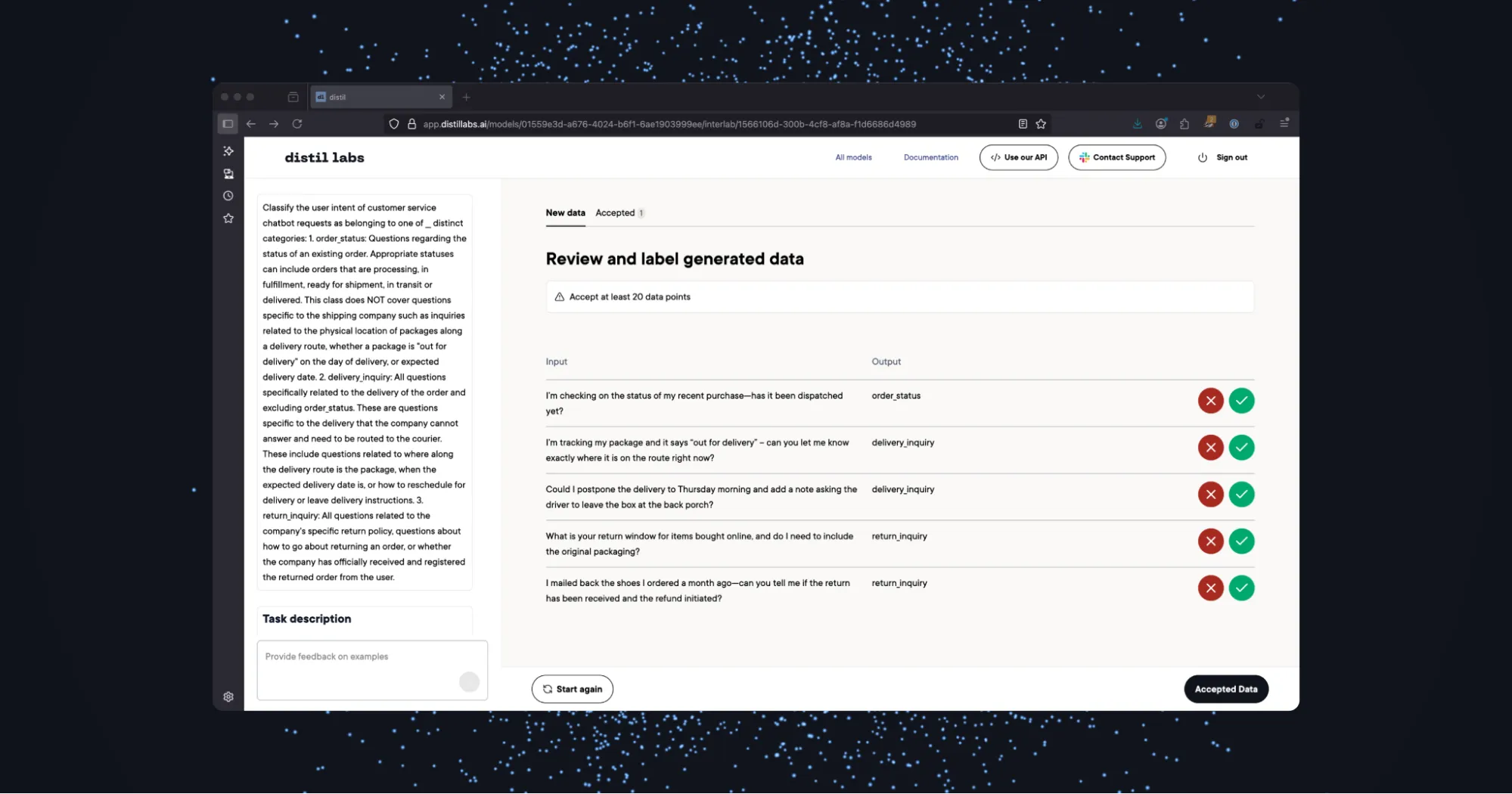
Step 2: Review and Label Generated Training Data.
With distil labs, you have the option to either upload real-world labeled examples or interactively label generated examples based on your original prompt. For this tutorial, we’ll use the interactive labeling feature. Be sure to include at least 20 labeled examples for model distillation.
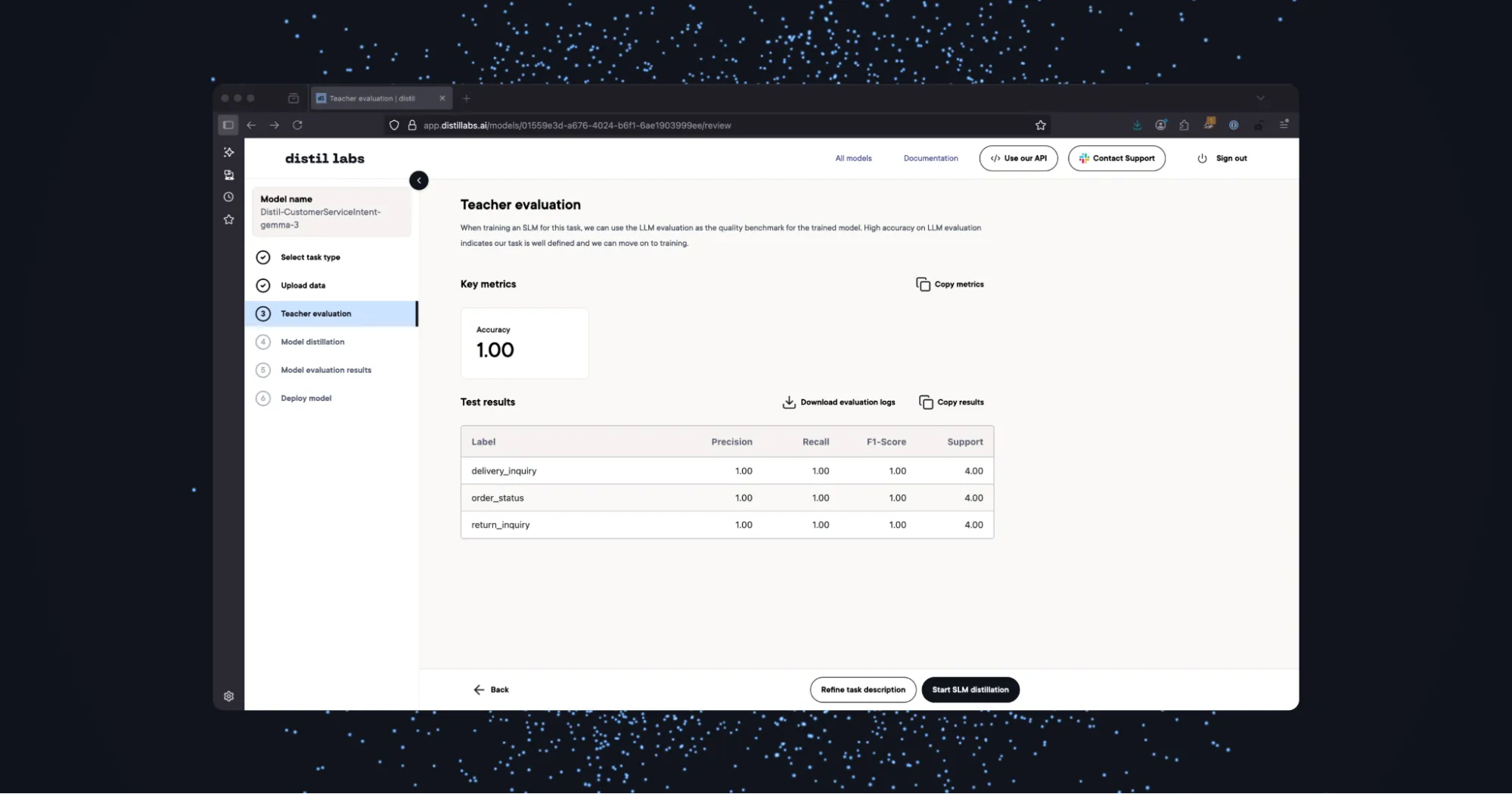
Step 3: Evaluate the Teacher Model.
In this step, the Teacher Model is automatically evaluated on its ability to classify user questions into one of our three different categories. If the performance of the Teacher Model is sufficient, as it is below, you can continue the distillation process by clicking on Start SLM Distillation.
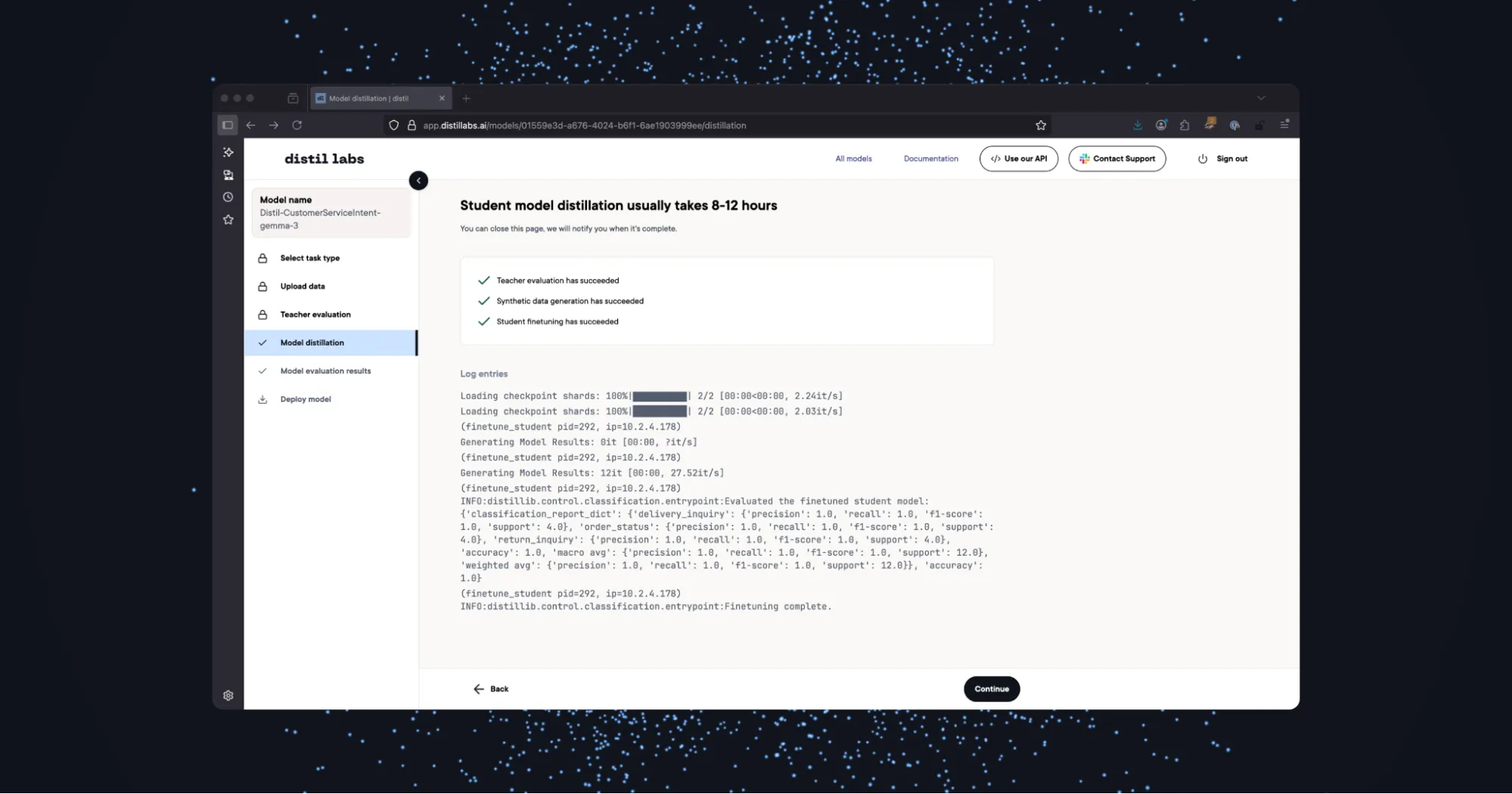
Note: The distillation process can take 8-12 hours and cannot be cancelled!
Step 4: Fine-Tune the Student Model.
This page will show the logs during the model distillation process. You will also get an email when your distillation job is complete.
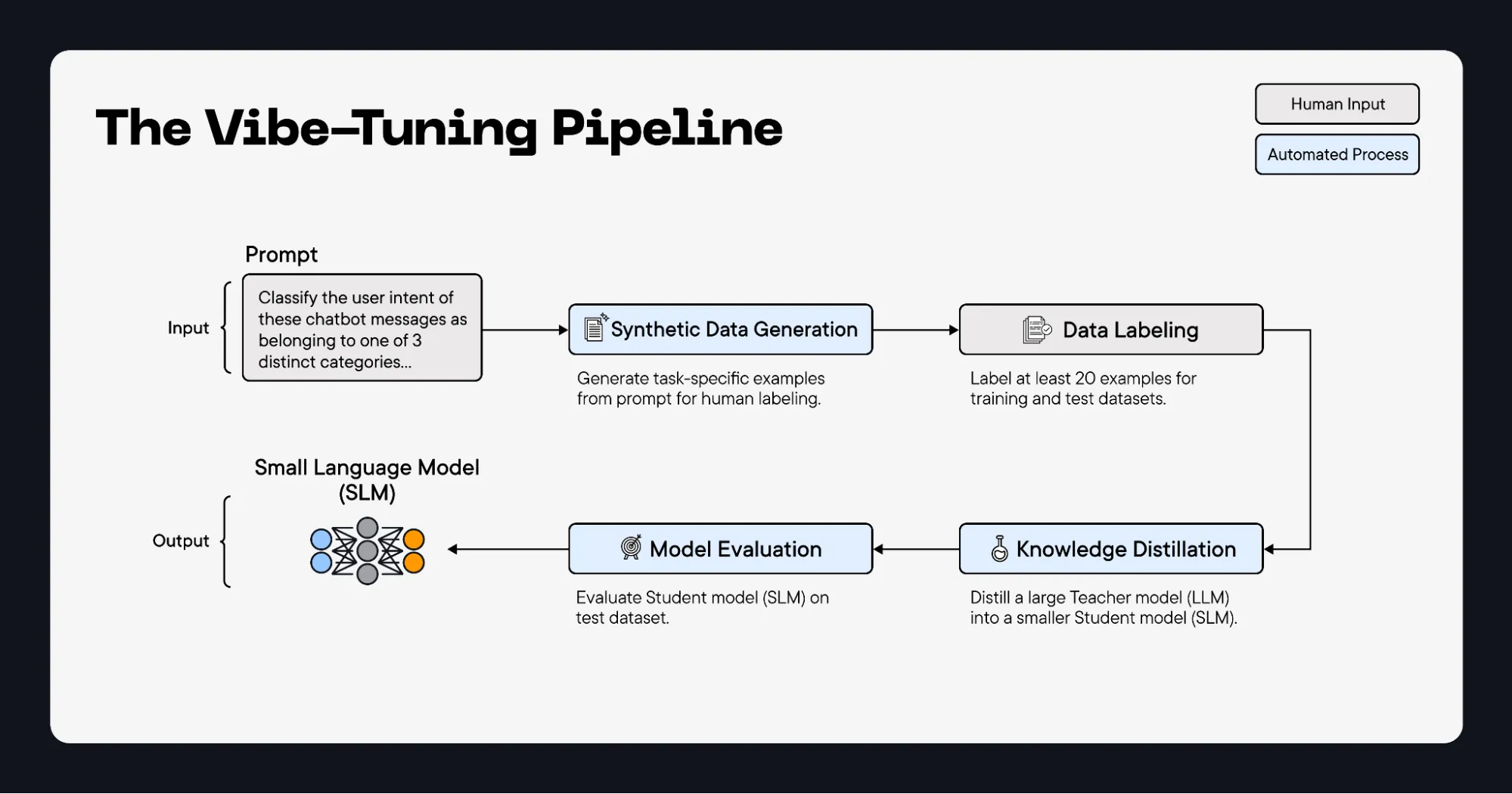
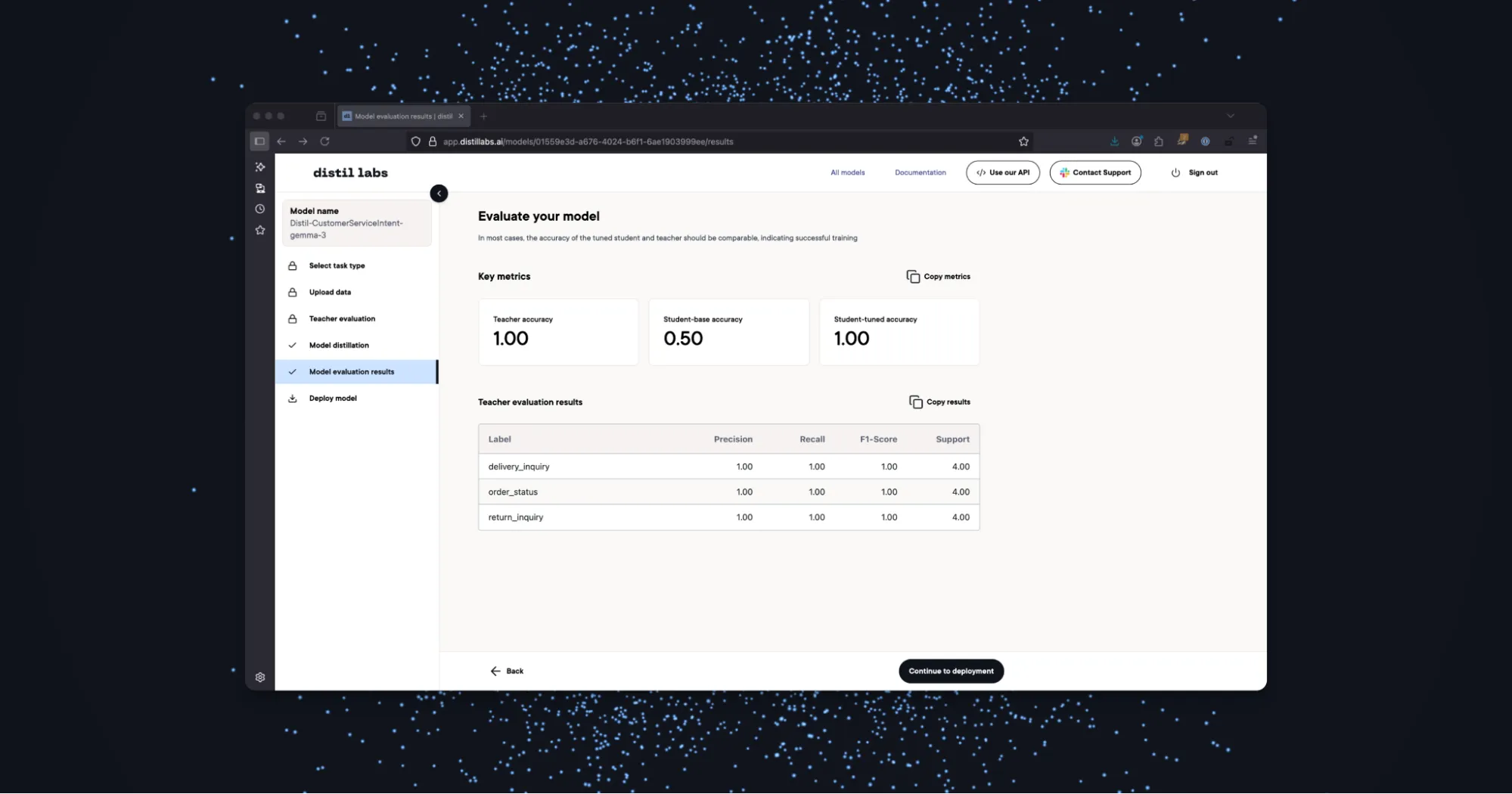
Step 5: Evaluate the Fine-Tuned Student Model.
After distillation is complete, the fine-tuned Student Model, our new SLM, will be automatically evaluated and benchmarked against the Teacher Model. Teacher accuracy refers to the accuracy of the Teacher Model, calculated in step three. Student-base accuracy is the accuracy of the untrained Student Model. Student-tuned accuracy is the final accuracy of the fine-tuned Student Model.
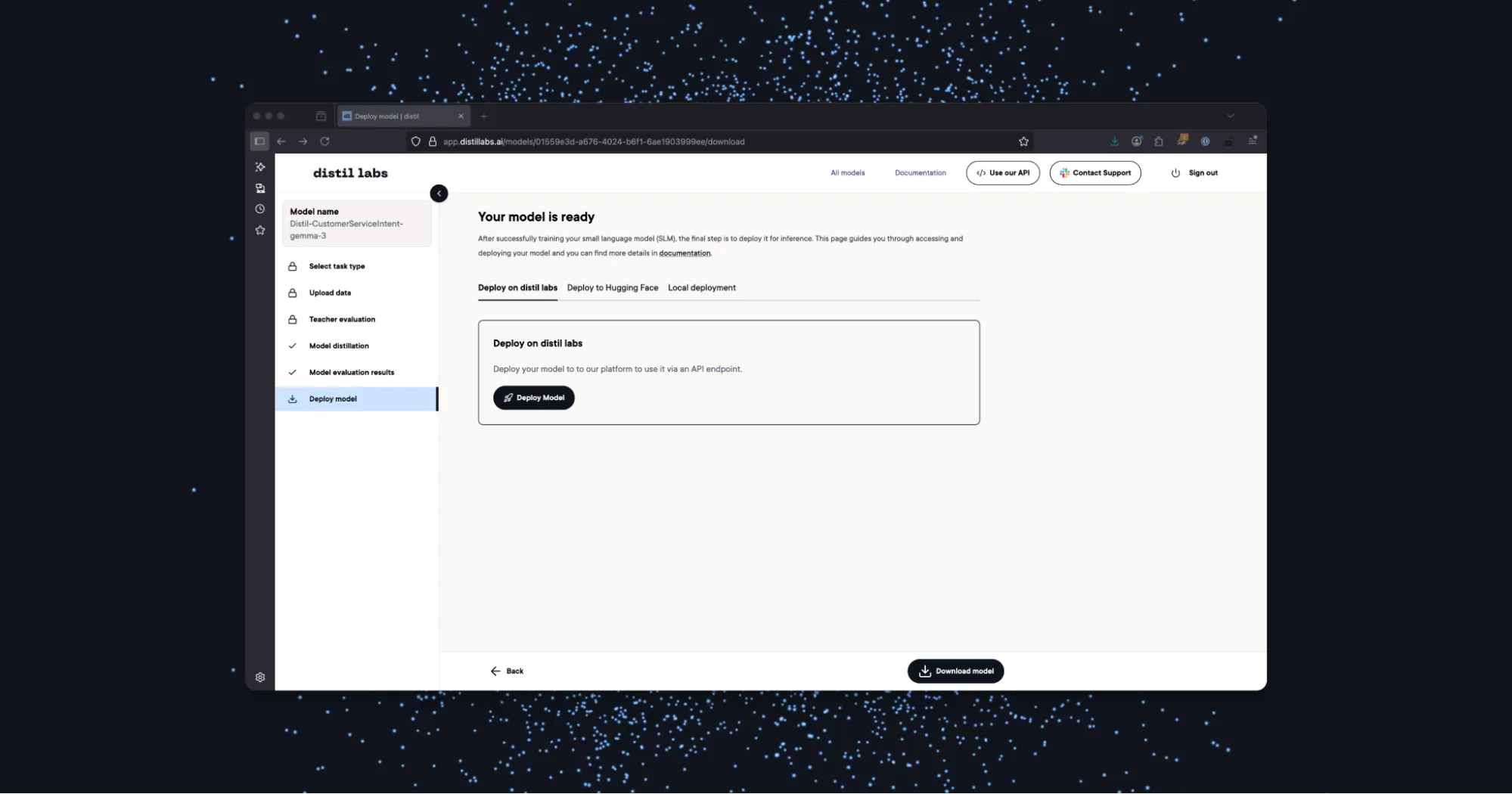
Step 6: Download Model and Deploy.
There are several options for deploying your new SLM for inference:
- Local deployment with vLLM or Ollama. This option allows you to run inference on your model in a private local environment. vLLM is optimized for high-throughput production serving, while Ollama is ideal for local development and model experimentation.
- Deploy with distil labs. With a single click, this option allows you to deploy your model to the distil labs platform and access it via an API endpoint.
Conclusion
Using smaller, specialized fine-tuned models is a robust alternative to prompt engineering large language models for downstream tasks including (but not limited to) classification, information extraction, and tool calling. Unfortunately, fine-tuning SLMs is a demanding task, which usually requires training data and advanced engineering skills to build and maintain distributed training pipelines that can accommodate large models.
In this post, we introduced vibe-tuning, a new technique that overcomes these challenges by allowing you to fine-tune a SLM with a single prompt. Vibe-tuning is powered by knowledge distillation, which distills the knowledge of a very large model into a much smaller SLM, while preserving or even improving its performance on specific tasks. We explained how and why vibe-tuning works and walked you through how to use the distil labs platform to fine-tune a SLM for intent classification.
For more information on how to use the distil labs platform and API to fine-tune SLMs for classification, open book question answering (RAG), closed book question answering, information extraction, and tool calling, check out our blog and documentation.
Link to the fine-tuned model on HF Hub.
Fine-tune your own SLM in a day for free. And then fine-tune another one (if you want). Sign up here to automatically receive two free distillation credits.
Recommended Resources
- Small Language Models are the Future of Agentic AI (Paper)
- Small Language Models (SLM): A Comprehensive Overview (Blog post)
- Gitara: How we trained a 3B Function-Calling Git Agent for Local Use (Blog post)
- distil labs: small expert agents from 10 examples (Blog post)
Sources
Bucher, M., Martini, M (2024, June 12). Fine-Tuned ‘Small’ LLMs (Still) Significantly Outperform Zero-Shot Generative AI Models in Text Classification. arXiv.
Hinton, G., Vinyals, O., Dean, J. (2015, March 9). Distilling the Knowledge in a Neural Network. arXiv.
Karpathy, A. (2024, July 31). Vibe coding tweet [Tweet]. X.
Meincke, L., Mollick, E., Mollick, L., & Shapiro, D. (2025, May 5). Prompting Science Report 1: Prompt Engineering is Complicated and Contingent. SSRN.
OpenAI. (2025, April 29). Sycophancy in GPT-4o: what happened and what we’re doing about it. OpenAI.
Parthasarathy, V. B., Zafar, A. K., Shahid A. (2024, Aug.). The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs: An Exhaustive Review of Technologies, Research, Best Practices, Applied Research Challenges and Opportunities (Version 1.0). CeADAR Connect Group.
Prompt Engineering Guide. (2025, Aug. 29). Prompt Engineering Guide. Prompt Engineering Guide.