TL;DR
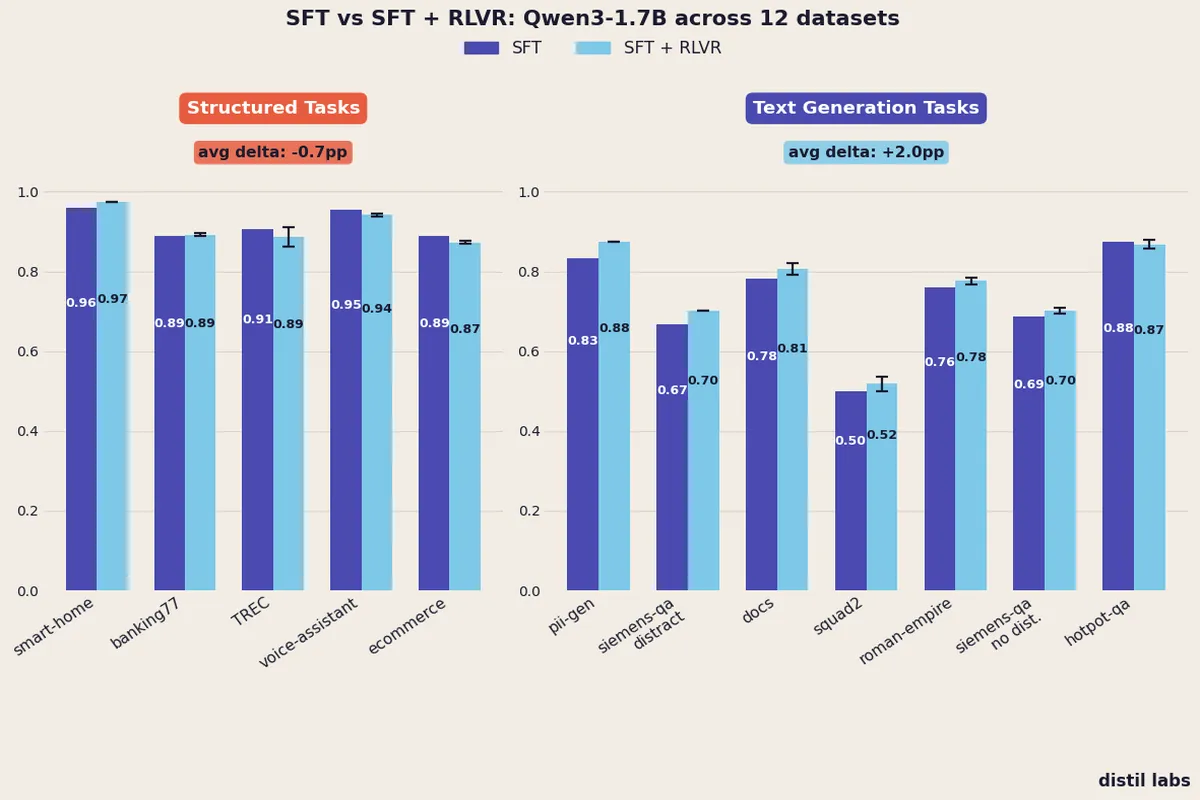
- Adding an RLVR stage after SFT consistently improves text generation tasks: +2.0pp average across 7 datasets, with no dataset showing a regression.
- For structured tasks (classification and function calling), RLVR provides no reliable benefit: -0.7pp average, with clear regressions on ecommerce and voice assistant tasks.
- The practical implication: your training recipe should match your task type. SFT alone is the right call for structured outputs; add RLVR when your task has a large output space and room to explore.
1. Introduction
Supervised fine-tuning works well. For the classification, PII redaction, and function calling tasks that sit at the core of the distil labs platform, SFT on synthetically generated data reliably produces small models that match or exceed 70B+ teacher performance. We have shown this across 10 benchmark datasets and more recently across 12 model families.
So why add reinforcement learning at all?
The honest answer is that the recent literature is compelling. DeepSeek-R1 showed that RL with verifiable rewards can elicit reasoning capabilities that SFT alone cannot, even from small models. The Hugging Face Open-R1 team reproduced the key results. Yue et al. (NeurIPS 2025) and Chu et al. (ICML 2025) have debated whether RL actually teaches new capabilities or simply sharpens what the model already knows. Practitioners at Predibase have reported meaningful accuracy gains on exploratory tasks.
We wanted to go deeper and explore the question: does adding a reinforcement learning stage to our SFT pipeline actually help, and critically, when? This post reports what we found. We ran a controlled experiment on Qwen3-1.7B across 12 datasets spanning classification, function calling, and open-ended generation. The results landed cleanly on one side of a meaningful boundary, and the practical implications are concrete enough to act on. Based on these findings, the SFT + RLVR pipeline is now available on the distil labs platform — try it on your own task today.
2. What Is RLVR and How We Added It
Reinforcement Learning from Verifiable Rewards (RLVR) is a training approach where a model receives a reward signal based on whether its output is objectively correct, rather than from a learned human preference model. For structured tasks, “correct” means the classification label matches or the function call is equivalent. For generative tasks like QA, we use an LLM-as-a-Judge to provide a binary correctness signal.
The algorithm we used is GRPO (Group Relative Policy Optimization), introduced in DeepSeekMath. Unlike PPO, which requires maintaining a separate critic/value network, GRPO estimates advantages by comparing a group of rollouts for the same prompt. This eliminates the critic entirely, reducing memory and compute requirements to a level that fits within our small-model training budget.
In our pipeline, RLVR sits on top of SFT. The model first trains on our standard synthetic dataset generated by the distillation pipeline (see our technical approach for details on how we generate and validate training data). We then run a second training stage using GRPO with the same reward signal used for evaluation. Total dataset size is kept constant across all configurations: when an RLVR stage is added, that portion of the data is reserved for it, leaving less for SFT.
3. Results: The Task-Type Split
The results split cleanly along task type. Across the five structured datasets (classification and function calling), adding RLVR produces an average delta of -0.7pp, with two datasets regressing and no consistent wins. Across the seven generative datasets (QA and documentation), RLVR improves every single dataset with an average gain of +2.0pp. The pattern is unambiguous: RLVR reliably helps when the task requires open-ended generation and a judge can reward semantic correctness; it provides no reliable benefit when the task has a constrained output space and SFT has already captured the structure.
Structured Tasks: Classification and Function Calling
We tested RLVR on five structured datasets: banking77 intent classification, ecommerce product classification, TREC question type classification, a smart home function calling task, and a banking voice assistant.
| Dataset | Metric | SFT | Avg RLVR | Delta | Winner |
|---|---|---|---|---|---|
| smart-home | Tool call equivalence | 0.9605 | 0.9737 | +1.3pp | RLVR |
| banking77 | Accuracy | 0.8900 | 0.8925 | +0.3pp | Tie |
| TREC | Accuracy | 0.9050 | 0.8875 | -1.8pp | Tie |
| voice-assistant | Tool call equivalence | 0.9543 | 0.9417 | -1.3pp | SFT |
| ecommerce | Accuracy | 0.8900 | 0.8725 | -1.8pp | SFT |
| Average | -0.7pp |
Winner is marked “Tie” when the SFT score falls within one standard deviation of the Avg RLVR across configurations.
Text Generation Tasks: QA and Documentation
We tested RLVR on seven generative datasets: HotpotQA multi-hop reasoning, Roman Empire historical QA, Python documentation generation, closed-book SQuAD 2.0, PII redaction, and two variants of a Siemens microcontroller QA task (with and without distractor passages).
| Dataset | Metric | SFT | Avg RLVR | Delta | Winner |
|---|---|---|---|---|---|
| pii-gen | LLM-as-a-Judge | 0.8333 | 0.8750 | +4.2pp | RLVR |
| siemens-qa-distractor | LLM-as-a-Judge | 0.6667 | 0.7014 | +3.5pp | RLVR |
| docs | LLM-as-a-Judge | 0.7826 | 0.8063 | +2.4pp | RLVR |
| squad2 | LLM-as-a-Judge | 0.5000 | 0.5181 | +1.8pp | RLVR |
| roman-empire | LLM-as-a-Judge | 0.7609 | 0.7768 | +1.6pp | RLVR |
| siemens-qa-nodistractor | LLM-as-a-Judge | 0.6875 | 0.7014 | +1.4pp | RLVR |
| hotpot-qa | LLM-as-a-Judge | 0.8750 | 0.8683 | -0.7pp | Tie |
| Average | +2.0pp |
4. Why the Split? The Intuition
The pattern across these 12 datasets fits a coherent story. Understanding why it holds helps you apply the lesson to tasks we have not tested.
Structured tasks have constrained output spaces where SFT has already done the heavy lifting. A classification task with 77 intents is hard, but once the model has trained on high-quality labeled examples, it already achieves strong accuracy. At that point, applying GRPO creates a specific problem documented in Multi-Task GRPO: when the SFT-trained model gets most answers right, rollout groups for a given prompt all produce the same reward. Group-relative advantage is zero, no gradient flows, and the RL training produces no useful parameter updates. The DAPO paper describes the same issue at the algorithm level: its Dynamic Sampling technique explicitly filters out prompts where all rollouts succeed, or all fail, because those prompts carry no learning signal.
This is the zero-gradient problem: RLVR literally cannot improve a model that already performs well on structured tasks after SFT. The regressions on ecommerce and voice-assistant likely come from the optimizer making small noisy updates when gradients are near zero, slightly disrupting the fine-tuned representations.
Generative tasks have larger output spaces where RL exploration finds improvements SFT misses. When the correct answer to a QA question can be expressed in dozens of valid phrasings, an SFT loss penalizes any phrasing that does not match the training label exactly, even if it is semantically correct. RLVR sidesteps this problem: the LLM-as-a-Judge reward fires on semantic correctness, so the model can discover better-phrased answers that SFT would have suppressed. This is consistent with the ICML 2025 finding that SFT memorizes training examples while RL generalizes across them.
There is also a mechanistic explanation from Matsutani et al.: RL compresses incorrect reasoning trajectories while SFT expands correct ones. These are complementary effects. On structured tasks, there are very few incorrect trajectories left after SFT, so RL has nothing meaningful to compress. On generative tasks, the incorrect-path-compression that RL provides is what pushes performance past the SFT ceiling.
One important nuance: a NeurIPS 2025 best-paper runner-up argues that RLVR does not teach new capabilities but rather improves sampling efficiency by concentrating probability mass on correct answers that already exist in the model’s distribution. This framing does not change the practical recommendation, but it sets expectations correctly. If your model cannot approach a task after SFT, RLVR will not rescue it. The gains on generative tasks come from the model already having the right answers in its distribution and RL helping it find them more reliably at inference time.
5. Practical Recommendations
The results suggest a simple decision rule. Match your training recipe to your task type.
| Task Type | Recommended Approach | Rationale |
|---|---|---|
| Classification | SFT only | Constrained output space; SFT handles it; RLVR hits zero-gradient problem |
| Function calling (strict schema) | SFT only | Same as classification; sparse binary reward provides minimal RL signal |
| Function calling (flexible equivalence) | Consider SFT + RLVR | RL helps when reward recognizes semantic equivalence; see smart-home result |
| Open-book QA | SFT + RLVR | Large output space; RL finds better phrasings; judge reward captures semantic correctness |
| Information extraction / generation | SFT + RLVR | pii-gen result confirms; generative rewriting benefits from RL exploration |
| Documentation generation | SFT + RLVR | Consistent improvement on docs dataset across all tested configurations |
The Predibase analysis reaches the same conclusion from a different angle: SFT is best for structured datasets with sufficient labels, while RL shines in exploratory learning where the output space rewards creative solutions. The task type taxonomy we already use on the distil labs platform (classification, information extraction, tool calling, open-book QA, closed-book QA) maps almost directly onto this recommendation table.
6. Experimental Details
Model: Qwen3-1.7B. We chose this model because it sits in the range where small-model RL instability, documented by the Hugging Face Open-R1 team, is a real concern. Models smaller than 7B converge more slowly with GRPO; choosing 1.7B gives us a realistic test of whether RLVR is practically viable at the scale we target.
Training framework: TRL, used for both the SFT and RLVR stages. This keeps the infrastructure consistent and ensures any differences in outcome come from the training objective.
RLVR data fractions tested: We tested three configurations varying the fraction of training data reserved for the RLVR stage and epoch count:
- 0.2 fraction, 4 epochs
- 0.3 fraction, 2 epochs
- 0.4 fraction, 2 epochs
The remaining fraction goes to the SFT stage in each configuration. Not every configuration was run on every dataset; the “Avg RLVR” column in the tables above reports the average score across all configurations that were run for that dataset. The “Winner” determination uses this average and its standard deviation (see raw results table below).
Rewards: For classification, we use label accuracy. For function calling, we use tool call equivalence. For all open-ended generation tasks, we use the same binary LLM-as-a-Judge scorer used in our standard benchmark evaluation.
Full results table:
| Dataset | SFT | RLVR (0.2, 4ep) | RLVR (0.3, 2ep) | RLVR (0.4, 2ep) | Avg RLVR | Best RLVR | Winner |
|---|---|---|---|---|---|---|---|
| banking77 | 0.8900 | 0.8950 | — | 0.8900 | 0.8925 ± 0.0035 | 0.8950 | Tie |
| ecommerce | 0.8900 | 0.8700 | — | 0.8750 | 0.8725 ± 0.0035 | 0.8750 | SFT |
| TREC | 0.9050 | 0.8700 | — | 0.9050 | 0.8875 ± 0.0247 | 0.9050 | Tie |
| smart-home | 0.9605 | 0.9737 | — | 0.9737 | 0.9737 ± 0.0000 | 0.9737 | RLVR |
| voice-assistant | 0.9543 | 0.9442 | — | 0.9391 | 0.9417 ± 0.0036 | 0.9442 | SFT |
| hotpot-qa | 0.8750 | 0.8600 | 0.8650 | 0.8800 | 0.8683 ± 0.0104 | 0.8800 | Tie |
| roman-empire | 0.7609 | 0.7826 | — | 0.7709 | 0.7768 ± 0.0083 | 0.7826 | RLVR |
| docs | 0.7826 | 0.8103 | 0.7905 | 0.8182 | 0.8063 ± 0.0143 | 0.8182 | RLVR |
| squad2 | 0.5000 | 0.5222 | 0.5333 | 0.4989 | 0.5181 ± 0.0176 | 0.5333 | RLVR |
| pii-gen | 0.8333 | 0.8750 | 0.8750 | 0.8750 | 0.8750 ± 0.0000 | 0.8750 | RLVR |
| siemens-qa-nodistractor | 0.6875 | 0.7083 | 0.6944 | 0.7014 | 0.7014 ± 0.0070 | 0.7083 | RLVR |
| siemens-qa-distractor | 0.6667 | 0.7014 | — | 0.7014 | 0.7014 ± 0.0000 | 0.7014 | RLVR |
A dash (—) indicates the configuration was not run for that dataset. Winner is labeled “Tie” when SFT falls within one standard deviation of the RLVR average.
SFT stage: Standard distil labs pipeline, ~10,000 synthetic examples per task generated by the teacher model and filtered through our validation pipeline. Full methodology is in the 12-model benchmark post.
7. Conclusion
The question we set out to answer was whether adding a reinforcement learning stage to our SFT pipeline actually helps, and when. The answer is clear: RLVR reliably improves generative tasks (+2.0pp average, 6 wins and 1 tie out of 7) and provides no reliable benefit on structured tasks (-0.7pp average, 2 wins but also 2 regressions out of 5).
This follows a consistent thread in the literature: SFT is good at learning formats and constrained outputs, while RL is good at exploring large output spaces. What the experiment adds is that the boundary between “RL helps” and “RL doesn’t help” maps onto a distinction ML engineers already use when thinking about task type. You do not need to run an ablation on every new task. You need to know whether your task is constrained or generative.
If you have a task in mind, start with a short description and a handful of examples. Sign up and start distilling.