Voice assistants in production today almost universally rely on cloud LLMs for the “brain” stage: classifying intent, extracting structured data, and tracking dialogue state across turns. The approach works, but it introduces 700+ms of latency on every single turn, pushes total pipeline response times past the threshold where conversations feel natural, and sends customer data to third-party APIs for processing. For voice workflows with defined intents and bounded slot types, like banking, insurance, telecom, or customer service, this is a significant amount of unnecessary overhead.
The core issue is that general-purpose LLMs are wildly overqualified for the job. Routing “cancel my credit card ending in 4532” to the right function does not require a trillion-plus parameter model sitting behind an API call. It requires a fast, accurate specialist that understands your specific intent taxonomy and can extract structured data reliably across multi-turn conversations.
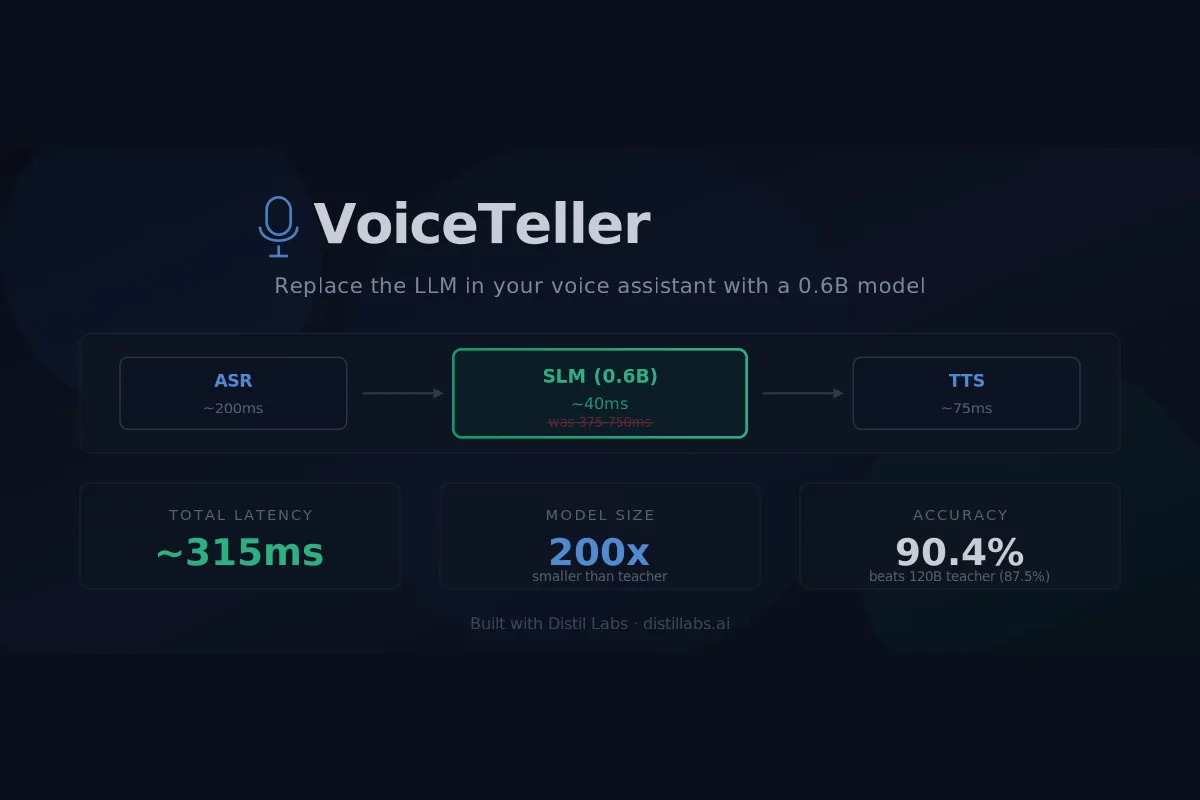
That specialist is a fine-tuned small language model (SLM). In this post, we make the case that SLMs are the right architecture choice for the brain of a voice assistant: they are faster, more accurate on bounded tasks, cheaper to operate, and keep customer data private. We back this up with numbers from a banking voice assistant we built called VoiceTeller, where a fine-tuned SLM running at 40ms per turn (200m with network latency) outperforms the 120B teacher model it was distilled from.
If you have voice workflows in mind, get in touch and we’ll show you what an SLM can do for your specific use case.
Voice Pipelines are Unnecessarily Slowed down by LLMs
Enterprise voice assistants follow a cascaded pipeline where latencies stack across three stages: ASR (speech-to-text), then the LLM (intent and reasoning), then TTS (text-to-speech). Conversational UX research consistently places the threshold for natural-feeling interaction at 500–800ms total, and cloud LLMs routinely push the pipeline well past that boundary because the brain stage alone consumes over 70% of total processing time.
| Component | Cloud LLM Pipeline | SLM Pipeline |
|---|---|---|
| ASR (Speech-to-Text) | 200–350ms | ~200ms |
| LLM / SLM (Brain) | 700ms - 2s | ~200ms |
| TTS (Text-to-Speech) | 160-250ms | ~150ms |
| Total | 1060–2.6s | ~550ms |
Replacing the cloud LLM with a locally-running SLM drops the brain stage from hundreds of milliseconds to roughly 40ms (200m with network latency), bringing the full pipeline down to around 315ms. That is well within the range where conversations feel responsive and natural, rather than sluggish and turn-by-turn.
This is not a marginal optimization. For the people making decisions about voice infrastructure, it is the difference between a product that users tolerate and one they actually prefer, and it directly impacts completion rates, handle times, and channel adoption.
Smaller Can Mean More Accurate (and That Might Surprise You)
The most common objection to replacing an LLM with an SLM is accuracy. The assumption is intuitive: a bigger model should be a smarter model. For general-purpose tasks that span the full breadth of language, that is usually true. But for bounded voice workflows with defined intents and structured outputs, fine-tuned SLMs routinely match or exceed models that are 100–200x their size.
We tested this with a banking voice assistant that handles 14 operations including balance checks, transfers, card cancellations, fraud reporting, and more. The SLM needs to classify intent, extract the right details from what the user said, and carry context across multiple turns of conversation.
| Model | Parameters | Single-Turn Tool Call Accuracy |
|---|---|---|
| GPT-oss-120B (teacher) | 120B | 87.5% |
| Fine-tuned SLM (Qwen3-0.6B) | 0.6B | 90.9% |
| Base Qwen3-0.6B (no fine-tuning) | 0.6B | 48.7% |
The fine-tuned SLM exceeds the 120B teacher by over 3 percentage points while being 200x smaller, and the base model without fine-tuning sits at 48.7%, which is essentially unusable for production. Two things explain this counterintuitive result. First, the fine-tuning pipeline filters out the teacher’s mistakes during data validation, meaning the student trains only on high-quality examples rather than inheriting the teacher’s failure modes. Second, and more importantly, the SLM specializes entirely on one task: it allocates all of its capacity to your specific intent taxonomy, while a general-purpose LLM has to spread that capacity across everything from poetry to code generation. For narrow, well-defined workflows, the specialist wins.
It is worth noting that this applies specifically to bounded tasks with defined intents and structured outputs. Open-ended conversational generation still benefits from larger models, but that is not what voice assistants with defined workflows need.
Accuracy also compounds across turns in voice, which makes these differences even more significant in practice. The probability of getting every turn right is roughly the single-turn accuracy raised to the number of turns: at 90.9%, a 3-turn conversation succeeds about 75% of the time, while at 48.7% (the base model without fine-tuning) that same conversation drops to roughly 11.6%. Every percentage point of improvement has an outsized effect on conversation-level reliability, which is precisely why fine-tuning is not optional for voice workloads.
Latency Is Just the Start
Latency is the most visible benefit of switching to an SLM, but the business case extends well beyond response speed. Replacing the cloud LLM changes the cost structure, privacy posture, and reliability profile of the entire voice stack.
Latency: The brain stage drops from 375–750ms to ~40ms per turn, bringing the total pipeline from 680–1300ms down to around 315ms, comfortably within the threshold for natural conversation.
Accuracy: Fine-tuned SLMs match or exceed LLMs on bounded tasks. In the banking benchmark above, a 0.6B model outperformed a 120B teacher, and larger SLMs in the 1B–4B range offer even more headroom for complex intent taxonomies.
Cost: Self-hosted inference eliminates per-token API fees entirely. For high-volume voice operations processing millions of turns per day, the difference between cloud LLM pricing and hosted SLM inference is substantial, often 50-90% cheaper per inference. If you self-host the model, the electricity costs are negligible making SLMs even more attractive.
Privacy: Customer data never leaves your infrastructure. There are no API calls to third-party providers, which matters in banking, healthcare, insurance, and any industry where data residency and compliance requirements are non-negotiable.
Reliability: No network dependency means no API outages and no rate limits during traffic spikes. The model runs on your hardware and is available whenever your systems are.
The right way to think about SLMs in voice is not as a cheaper and just as accurate alternative to LLMs. They are purpose-built tools that outperform general-purpose models on the specific job they were designed for, while simultaneously being faster, cheaper, more private, and more reliable.
VoiceTeller: See It Working
Everything above is backed by a working system you can try yourself. VoiceTeller is a fully functional banking voice assistant that you can clone and run locally, built to demonstrate that SLMs can replace the LLM in a real voice pipeline without compromising on accuracy or conversational capability. The architecture follows the standard voice cascade with one critical design choice: the SLM never generates user-facing text. It only outputs structured JSON that represents what the user wants and what details they provided, and a deterministic orchestrator handles all response generation through templates and conversation state management.
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ ASR Module │ │ Fine-tuned │ │ TTS Module │
│ │───>│ SLM │───>│ │
│ ~200ms │ │ ~40ms │ │ ~75ms │
└───────────────┘ └───────────────┘ └───────────────┘
▲ │ ▼
┌──────┴──────┐ ┌───────────────┐ ┌──────┴──────┐
│ Microphone │ │ ORCHESTRATOR │ │ Speaker │
└─────────────┘ │ - Intent exec │ └─────────────┘
│ - Templates │
│ - State mgmt │
└───────────────┘This separation is deliberate and worth highlighting for anyone designing voice architectures. The SLM handles the hard part: understanding what the user wants and extracting structured data from noisy, natural speech. The orchestrator handles the predictable part: checking whether it has everything it needs to act, asking for any missing details, and executing the request. Because the response generation is deterministic, latency is bounded, responses are always well-formed, and brand voice stays consistent regardless of what the model outputs.
What It Looks Like in Practice
The assistant handles real conversational patterns that any production voice system needs to support: understanding intent from natural and often messy speech, gathering missing details across multiple turns, and adapting when users change their mind mid-conversation.
Gathering details across turns:
User: I want to transfer some money
Bot: Could you provide the amount, which account to transfer from,
and which account to transfer to?
User: 200 dollars from checking to savings
Bot: Done. Transferred $200.00 from checking to savings.Handling messy real-world speech:
User: um I need to like cancel my uh debit card
Bot: Could you provide the last 4 digits?
User: 4532
Bot: Done. Your debit card ending in 4532 has been cancelled.Mid-conversation intent change:
User: I need to cancel my card
Bot: Could you provide credit or debit, and the last 4 digits?
User: Actually, what's my checking balance first?
Bot: Your checking balance is $2,847.32.These are the scenarios that break base models and make fine-tuning essential: carrying context across turns, parsing intent through filler words and transcription noise, and recognizing when a user has changed direction. The full source code for the end-to-end voice assistant, as well as the trained SLMs are available in the GitHub repository.
How to train your own SLM with distill
The workflow behind VoiceTeller is generic across voice assistant use cases. If you have defined intents, whether for banking, insurance, telecom, healthcare, or any other domain with structured workflows, you can fork the project, adapt it for your domain, and train your own assistant for less than $100.
What you need is a description of your intent taxonomy and 50 example conversations covering your workflow. The distil labs platform handles everything else (synthetic data generation, fine-tuning, evaluation) meaning your effort is minimal.
The choice of base model depends on your deployment constraints. Models around 0.6B parameters run on almost anything, including laptops and edge devices, while models in the 1B–4B range offer more capacity for complex intent taxonomies and still run locally with minimal hardware. Our benchmarking study covers how to choose the right base model for your specific task and accuracy requirements.
If your voice assistant currently runs on a cloud LLM, you are paying for latency you don’t need, sending customer data to third-party providers, and relying on a model that is overqualified for the job. A fine-tuned SLM is faster, more accurate on your specific task, cheaper to run, and keeps all data private. If you have voice workflows in mind, get in touch and we’ll show you what an SLM can do for your specific use case.
distil labs* trains task-specific small language models that match LLM accuracy at 50–400x smaller size. Docs · GitHub · *Slack