
Introduction
In this blog post, we show how we trained a small language model (SLM) to outperform large language models (LLMs) in the task of analysing cyber security logs without compromising privacy. Over the past few months, we partnered with Octodet [https://www.octodet.com/] to solve this challenging problem.
Octodet is a team of cybersecurity specialists focused on creating a seamless security experience, developing innovative tools and delivering services that make cybersecurity straightforward and accessible for their clients. To help their customers, they developed Kindi, a small language model designed to assist cybersecurity investigations with the ability to reason over logs, alerts, and digital evidence.
Context
LLMs have been trained on large amounts of publicly available data and perform well on a range of generalist tasks. They do, however, fall short in the face of complex and domain-specific problems. One such problem in cybersecurity is the expert analysis of system logs to determine whether or not observed behaviour is legitimate or not. Our target, therefore, is to finetune an SLM that outperforms an LLM for this specific task.
The knowledge needed to analyse logs properly exists across several sources: books, documentation, frameworks such as the MITRE ATT&CK framework. Much of this information is continuously updated as the industry gathers new learnings and this poses a challenge to LLMs that have been trained on data up to a specific point in time. Furthermore, there are privacy constraints that restrict certain data being sent to open LLMs. Such a hard constraint means it is sometimes impossible to even get started.
There are ultimately two key challenges we are trying to solve:
- Train a language model to effectively analyse and categorise system logs for potential cybersecurity threats
- Enable the model to be deployed by Octodet on their own environment so they can adhere to strict privacy standards of their customer data.
Solution
For training a model to better analyse system logs, we need to embed new knowledge into that model given that the base model itself does not perform well in the task of analysing logs. This is where the power of finetuning comes in. Small language models are incredibly adaptable and when specialised via finetuning, their performance on a task-specific problem can outperform LLMs that are more than 500x larger.
The distil labs developer platform makes finetuning SLMs easy. We support a range of NLP tasks such as classification, tool-calling and question-answering. We also support closed-book question-answering, a subtype of question-answering for situations where you want to embed the knowledge contained in unstructured data into a model. This allows a model to answer questions using its internal knowledge without requiring access to external sources.
Closed-Book Question Answering
RAG is a common approach to hook up external data sources so that a language model can have access to relevant knowledge at runtime for answering questions. RAG systems, however, are only as good as the retrieval component. It has been shown that this retrieval fails in even simple settings and leads to situations where certain documents in a vector store are mathematically impossible to retrieve based on an input query [1]. This research conducted by Deepmind shows this to be true for even simple cases.
Another issue with RAG is the semantic gap that can exist between a user’s query and the chunk of text that contains the answer. For Octodet’s use-case, the input query was a collection of system logs and the relevant knowledge to analyse these logs was spread across books, documentation and frameworks such as MITRE ATT&CK. This is mismatch between the logs and text-heavy documentation makes it difficult to have an effective retrieval system. One solution to overcome this is to adapt a language model to incorporate new domain-specific knowledge using supervised fine-tuning [2].
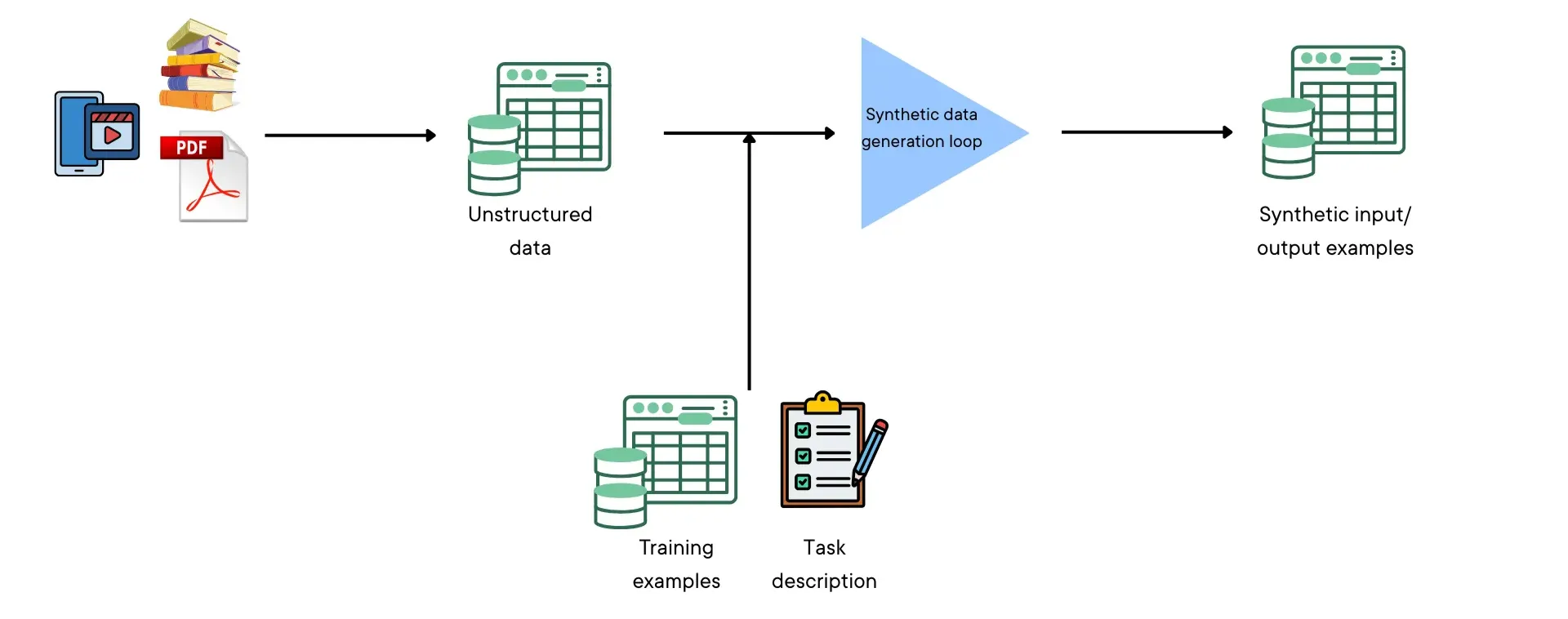
We started off with several sources of unstructured data in the cybersecurity domain such as:
- LOLBAS: a project that documents a specific type of attack strategy where hackers use legitimate, pre-installed Windows tools to perform malicious actions
- LOLDrivers: legitimate, digitally signed Windows drivers that have known vulnerabilities
- MITRE ATT&CK framework: a comprehensive knowledge base of adversary tactics and techniques based on real-world, post-compromise cyberattack observations.
- IR Playbooks: a structured set of guidelines and procedures that organisations follow to detect, respond to, and recover from cybersecurity incidents
Some of these datasets contain information that may be seen in logs when an incident has occurred (i.e. LOLBAS, LOLDrivers) and other datasets contain information that allows us to analyse such an incident.
The first step was to preprocess this into a single homogenous dataset. How we combined these disparate data sources was hugely consequential to the downstream performance gain we saw. Closed-book question answering works by generating synthetic training data from unstructured data. A single example in a training dataset contains an input and corresponding output. For this use-case, an input consisted of system logs and the output contained a detailed analysis of those logs.
Below is an example input/output pair:
Input:
{'rule': {'description': 'Detects requests attempting to navigate directories.'},
'network': {'protocol': 'https/tls1.2'},
'alert_count': 1,
'event': {'category': 'fortinet_fortiweb'},
'kibana': {'alert': {'original_event': {'ingested': '2025-01-21T21:59:20Z'}}},
'severity': 'high',
'alert_description': 'network event on firewalllogs created high alert WAF - Path Traversal Attempts.',
'@timestamp': '2025-01-21T22:03:01',
'fortinet': {'firewall': {'src_port': '35046',
'srccountry': 'Netherlands',
'http_agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41',
'http_retcode': '200',
'dst': '172.1.02.20',
'src': '172.7.2.40',
'http_refer': 'none',
'dst_port': '8080',
'http_host': 'domain.com',
'http_url': '/logs/downloadMainLog?fname=../../../../../../..///config/MPXnode/www/appConfig/userDB.json'}},
'name': 'WAF - Path Traversal Attempts'}
Output:
Investigation
1. What is happening?
The SOC detected a Path Traversal attempt targeting domain.com from source IP 172.7.2.40.
The suspicious HTTP request was:
\/logs\/downloadMainLog?fname=..\/..\/..\/..\/..\/..\/..\/\/\/config\/MPXnode\/www\/appConfig\/userDB.json
The request was not blocked by the WAF and the server responded with HTTP 200, indicating the request was successfully processed.
This implies that the targeted file (userDB.json) was likely retrieved, potentially exposing sensitive application configuration or user data.
Threat Intelligence check: source IP 172.7.2.40 is flagged as malicious by one TI vendor.
2. Why is it happening?
The attacker attempted to exploit the application's log download functionality using directory traversal (..\/..\/) to reach sensitive configuration files.
The targeted file (userDB.json) is consistent with a user database configuration file, which may contain usernames, hashed passwords, or application secrets.
This activity maps to:
MITRE ATT&CK T1190 – Exploit Public-Facing Application
The confirmed 200 OK response suggests that the attack was successful in retrieving data, not just probing.
3. How was the conclusion reached?
Explicit use of traversal pattern (..\/..\/) targeting a sensitive JSON config file.
HTTP 200 OK confirms the request was processed and the file likely returned.
Source IP marked as suspicious\/malicious by at least one vendor.
Possible exposure of user data or configuration secrets, enabling follow-up attacks such as credential compromise or privilege escalation.
Classification:
Confirmed ThreatWe generate synthetic data in an iterative manner by looping through each chunk of unstructured data and generating N examples for that chunk. As such, each chunk needs to contain the relevant knowledge that allows us to generate an input (system logs that may or may not contain malicious behaviour) AND an output (detailed analysis of the system logs). The preprocessing, therefore, involved combining the different datasets where relevant. For example, in the LOLBAS dataset, there is a section on the Cmstp.exe executable (Installs or removes a Connection Manager service profile) and it contains a reference to the MITRE ATT&CK technique T1218.003 (System Binary Proxy Execution: CMSTP). The MITRE ATT&CK dataset itself contains much more detail and context around T1218.003. In these situations, we combine the chunks of knowledge into a single chunk. Using this new enriched chunk, we can generate higher-quality examples (input/output pairs).
Unexpected challenges
One of the challenges we faced during the running of this pipeline was the total runtime. We have in place sensible defaults for the total allowed runtime of certain steps of our pipeline but we found that these do not work so well for closed-book QA where the unstructured data can be extraordinarily large. As such, we implemented a separate limit for this task, which allowed us to easily overcome this hurdle.
Results
Using the synthetically generated data, we fine-tuned a Llama 8B model using a range of different parameters (mainly varying across Lora rank). We used an LLM-as-a-judge approach to analyse and compare each subsection.
Each example output contains the following sections that make up the whole analysis:
- What is happening?
- Why is it happening?
- How was the conclusion reached?
- Classification (threat / no threat / inconclusive)
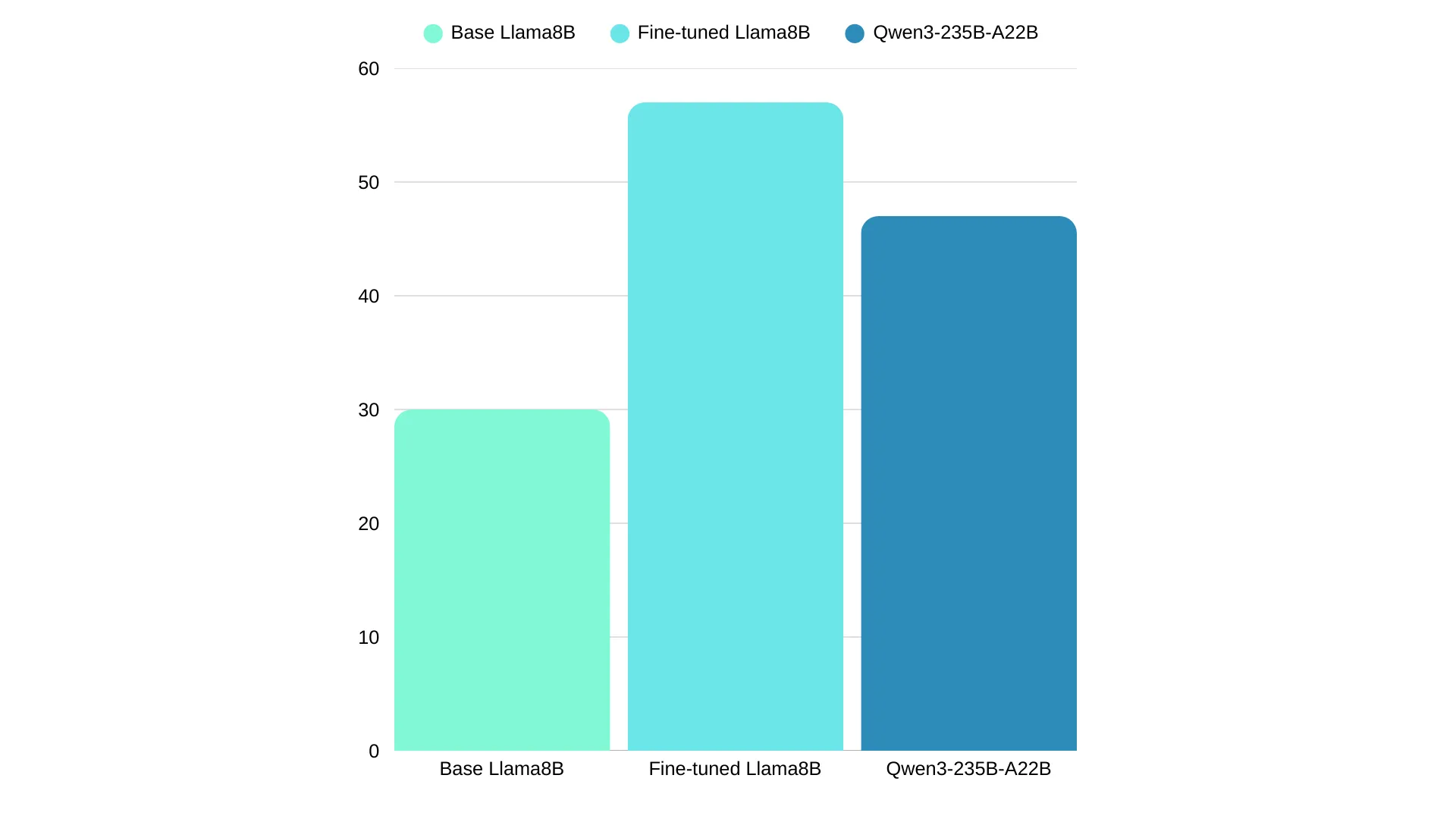
The ground truth answer and prediction for each section is passed to an LLM and scored out of 10 based on how closely the analysis in the prediction matches that of the ground truth answer. This means there is a total of 40 points to be scored per example (10 points for each of the 4 sections). We report the results on the base SLM, the fine-tuned SLM and the best performing LLM:
The fine-tuned Llama 8B model scored 57% whilst the best performing LLM scored 47%. Despite being ~30X smaller, the Llama 8B model punches far above its (FP16) weight, scoring 10% higher. When comparing only the classification section of the output (threat / no threat / inconclusive), the fine-tuned Llama 8B model scores 88% whilst Qwen3-235B-A22B scores 63%. We can also see that the performance of the base Llama8B is significantly lower than the fine-tuned SLM and the LLM. This huge performance gain is a strong signal that we have vastly improved the skills of the SLM for this particular task.
References:
- [1] On the Theoretical Limitations of Embedding-Based Retrieval, Orion Weller and Michael Boratko and Iftekhar Naim and Jinhyuk Lee (Google DeepMind, Johns Hopkins University), 2025
- [2] Injecting New Knowledge into Large Language Models via Supervised Fine-Tuning, Nick Mecklenburg and Yiyou Lin and Xiaoxiao Li and Daniel Holstein and Leonardo Nunes and Sara Malvar and Bruno Silva and Ranveer Chandra and Vijay Aski and Pavan Kumar Reddy Yannam and Tolga Aktas and Todd Hendry (Microsoft), 2024