TL;DR
We benchmarked 15 small language models across 9 tasks to find the best base model for fine-tuning. Here’s what we found:
Most tunable (biggest gains from fine-tuning): Liquid AI’s LFM2 family sweeps the top three spots, with LFM2-350M ranking #1 (average rank: 2.11) and LFM2-1.2B at #2 (3.44). These models absorb training signal more effectively than any other family we tested, delivering outsized improvements from fine-tuning relative to their compact size.
Best fine-tuned performance: The Qwen3 family dominates, claiming 4 of the top 6 spots. Qwen3-8B ranks #1 (average rank: 2.33), followed by Qwen3-4B-Instruct-2507 at #2 (3.33). The Llama family takes #3 and #4 (Llama-3.1-8B and Llama-3.2-3B, both at 4.11), with Qwen3-1.7B and Qwen3-0.6B rounding out the top 6. And if you need a model under 1.5B parameters, Liquid AI’s LFM2-1.2B punches well above its weight class, placing 7th overall and outperforming several larger competitors.
Fine-tuned SLMs can beat much larger models: fine-tuned Qwen3-4B matches or exceeds GPT-OSS-120B (a 30x larger teacher) on 8 of 9 benchmarks, with the remaining one within 3 percentage points. On SQuAD 2.0, the fine-tuned student beats the teacher by 19 points. This means you can get frontier-level accuracy at a fraction of the cost, running entirely on your own hardware.
Introduction
If you’re building AI applications that need to run on-device, on-premises, or at the edge, you’ve probably asked yourself: which small language model should I fine-tune? The SLM landscape is crowded (Qwen, Llama, Liquid AI’s LFM2, Gemma, SmolLM) and each family offers multiple size variants. Picking the wrong base model can mean weeks of wasted compute or a model that never quite hits production quality.
We ran a systematic benchmark to answer this question with data. Using the distil labs platform, we fine-tuned 15 models across 9 diverse tasks (classification, information extraction, document understanding, open-book QA, closed-book QA, and tool calling), then compared their performance against each other and against the teacher LLM used to generate synthetic training data.
This post answers four practical questions:
- Which model is the most tunable? (i.e., gains the most from fine-tuning)
- Which model produces the best results after fine-tuning?
- Which model has the best base performance? (before any fine-tuning)
- Can our best student actually match the teacher?
Question 1: Which Model is the Most Tunable?
Winner: LFM2-350M (average rank: 2.11)
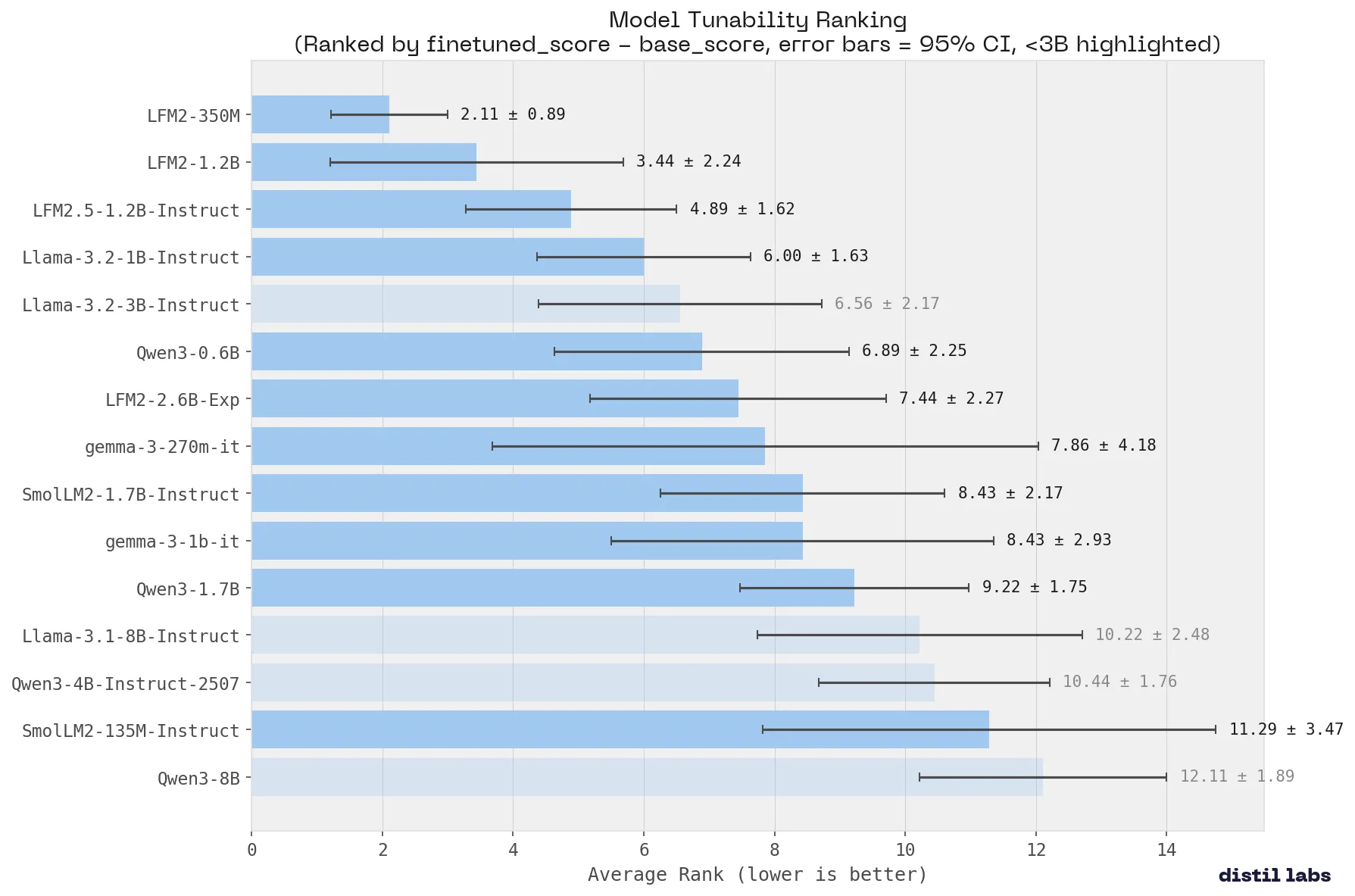
Tunability measures how effectively a model absorbs new training signal, calculated as the improvement from base to fine-tuned performance (finetuned_score - base_score). A highly tunable model responds strongly to task-specific training, making it an ideal candidate for fine-tuning workflows where you want maximum return on your training investment.
| Model | Average Rank | 95% CI |
|---|---|---|
| LFM2-350M | 2.11 | ±0.89 |
| LFM2-1.2B | 3.44 | ±2.24 |
| LFM2.5-1.2B-Instruct | 4.89 | ±1.62 |
| Llama-3.2-1B-Instruct | 6.00 | ±1.63 |
| Llama-3.2-3B-Instruct | 6.56 | ±2.17 |
| Qwen3-0.6B | 6.89 | ±2.25 |
Liquid AI’s LFM2 family sweeps the top three spots for tunability, and it’s not close. LFM2-350M takes #1 with the tightest confidence interval in the ranking (±0.89), meaning it improves consistently across every benchmark, not just a few. LFM2-1.2B and LFM2.5-1.2B-Instruct follow at #2 and #3.
This is a remarkable result given the size of these models. LFM2-350M has just 350 million parameters, yet it absorbs task-specific training signal more effectively than models 4-20x its size. For teams deploying on edge hardware or embedded devices, this means you can start with a tiny model and reliably close the gap to much larger alternatives through fine-tuning.
The larger models (Qwen3-8B, Qwen3-4B) rank near the bottom for tunability. This isn’t a weakness per se: they already perform well out of the box, so there’s less room to improve. But it highlights that the LFM2 architecture is particularly well-suited for the fine-tuning paradigm, where the goal is to specialize a compact model for a single task.
Key takeaway: Liquid AI’s LFM2 models offer the best return on fine-tuning investment of any family we tested. If you’re working with constrained hardware or need to maximize the value of task-specific training, the LFM2 family should be at the top of your list.
Question 2: Which Model Produces the Best Results After Fine-Tuning?
Winner: Qwen3-8B (average rank: 2.33)

| Model | Average Rank | 95% CI |
|---|---|---|
| Qwen3-8B | 2.33 | ±0.57 |
| Qwen3-4B-Instruct-2507 | 3.33 | ±1.90 |
| Llama-3.1-8B-Instruct | 4.11 | ±2.08 |
| Llama-3.2-3B-Instruct | 4.11 | ±1.28 |
| Qwen3-1.7B | 4.67 | ±1.79 |
| Qwen3-0.6B | 5.44 | ±2.60 |
The Qwen3 family dominates the top spots, with Qwen3-8B taking first place with the tightest confidence interval of any model in the ranking. Qwen3-4B-Instruct-2507 follows closely at #2, but its wider confidence interval (±1.90) suggests more variable performance across tasks.
The Llama family holds its own, with Llama-3.1-8B and Llama-3.2-3B tied at #3. Notably, the 3B Llama model matches the 8B variant, making it an attractive option when GPU memory is limited. Also worth noting: Liquid AI’s LFM2-1.2B places 7th overall (average rank: 5.89), a strong showing for a model with just 1.2B parameters, outperforming several larger competitors including SmolLM2-1.7B and gemma-3-1b-it.
Key takeaway: If you want the best possible fine-tuned model, Qwen3-8B is your top choice, with remarkably consistent performance across all benchmarks. For a strong alternative at half the parameter count, Qwen3-4B-Instruct-2507 remains highly competitive. And if you need a model under 1.5B parameters, LFM2-1.2B punches well above its weight class.
Question 3: Which Model Has the Best Base Performance?
Winner: Qwen3-8B (average rank: 1.67)

| Model | Average Rank | 95% CI |
|---|---|---|
| Qwen3-8B | 1.67 | ±0.46 |
| Qwen3-4B-Instruct-2507 | 3.11 | ±1.24 |
| Llama-3.1-8B-Instruct | 3.33 | ±1.53 |
| Qwen3-1.7B | 4.67 | ±1.22 |
| LFM2-2.6B-Exp | 6.67 | ±1.99 |
| Llama-3.2-3B-Instruct | 6.78 | ±1.38 |
As expected, base performance correlates with model size. Qwen3-8B leads with remarkably consistent performance across all benchmarks (lowest confidence interval of any model at ±0.46). The top three spots all go to 4B+ models.
Key takeaway: If you need strong zero-shot/few-shot performance without fine-tuning, larger models are still your best bet. But remember: this advantage shrinks significantly after fine-tuning, and a well-tuned 1B model can outperform a prompted 8B model.
Question 4: Can Our Best 4B Student Match the Teacher?
Yes. Qwen3-4B-Instruct-2507 matches or exceeds the teacher on 8 out of 9 benchmarks.
| Benchmark | Teacher | Qwen3-4B Finetuned | Qwen3-4B Base | Delta (Student vs Teacher) |
|---|---|---|---|---|
| TREC | 0.90 | 0.93 | 0.51 | +0.03 |
| Banking77 | 0.92 | 0.89 | 0.87 | -0.03 |
| Docs | 0.82 | 0.84 | 0.64 | +0.02 |
| Ecommerce | 0.88 | 0.90 | 0.75 | +0.03 |
| PII Redaction | 0.81 | 0.83 | 0.58 | +0.02 |
| Roman Empire QA | 0.75 | 0.80 | 0.65 | +0.05 |
| Smart Home | 0.92 | 0.96 | 0.97 | +0.04 |
| SQuAD 2.0 | 0.52 | 0.71 | 0.26 | +0.19 |
| Voice Assistant | 0.92 | 0.95 | 0.87 | +0.03 |
The fine-tuned 4B student beats the 120B+ teacher on 8 benchmarks and falls slightly short only on Banking77 (within 3 percentage points). The most dramatic improvement is on SQuAD 2.0 closed-book QA, where the student exceeds the teacher by 19 percentage points, a testament to how fine-tuning can embed domain knowledge more effectively than prompting.
Key takeaway: A 4B parameter model, properly fine-tuned, can match or exceed a model 30x its size. This translates to ~30x lower inference costs and the ability to run entirely on-premises.
Practical Recommendations
Based on our benchmarks, here’s how to choose your base model:
| Your Constraint | Recommended Model | Why |
|---|---|---|
| Maximum accuracy | Qwen3-8B | Best fine-tuned performance, most consistent across tasks |
| Strong accuracy, smaller footprint | Qwen3-4B-Instruct-2507 | Close to Qwen3-8B at half the parameters; matches 120B+ teacher |
| Very limited compute (<2B params) | Qwen3-0.6B or Llama-3.2-1B-Instruct | High tunability at minimal size |
| Maximum fine-tuning gains | LFM2-350M or LFM2-1.2B (Liquid AI) | Absorb training signal most effectively; best return on fine-tuning |
| Ultra-compact deployment | LFM2-350M (Liquid AI) | Just 350M params, yet #1 in tunability; ideal for embedded/IoT |
| No fine-tuning possible | Qwen3-8B | Best zero-shot/few-shot performance |
| Edge deployment (mobile, IoT) | Qwen3-0.6B or LFM2-350M | Strong fine-tuned results at minimal size; both under 1B params |
Next Steps
This benchmark is a living study, and we are actively working to make these results even more robust:
- Evaluate more models: The SLM landscape evolves rapidly. We plan to add newer releases like Qwen3.5, Phi-4, and Mistral variants as they become available.
- Run more iterations: Currently, our results are averaged over a limited number of runs. We’re expanding to more iterations per benchmark to tighten confidence intervals and ensure the rankings are statistically reliable.
- Expand benchmark coverage: We want to include additional task types like summarization, code generation, and multi-turn dialogue to give a fuller picture of model capabilities.
We’ll update this post as new data comes in. If there’s a specific model or task you’d like us to benchmark, let us know!
Methodology
We evaluated the following models:
- Qwen3 family: Qwen3-8B, Qwen3-4B-Instruct-2507, Qwen3-1.7B, Qwen3-0.6B. Note that we turned off thinking for this family to ensure an even playing field.
- Llama family: Llama-3.1-8B-Instruct, Llama-3.2-3B-Instruct, Llama-3.2-1B-Instruct
- LFM2 family (Liquid AI): LFM2-350M, LFM2-1.2B, LFM2-2.6B-Exp, LFM2.5-1.2B-Instruct
- SmolLM2 family: SmolLM2-1.7B-Instruct, SmolLM2-135M-Instruct
- Gemma family: gemma-3-1b-it, gemma-3-270m-it
For each model, we measured:
- Base score: Few-shot performance with prompting alone
- Finetuned score: Performance after training on synthetic data generated by our teacher (GPT-OSS 120B)
Our 9 benchmarks span classification (TREC, Banking77, Ecommerce), information extraction (PII Redaction), document understanding (Docs), open-book QA (Roman Empire QA), closed-book QA (SQuAD 2.0), and tool calling (Smart Home, Voice Assistant). For details on the evaluation setup and the benchmarks themselves, see our platform benchmarking post.
Results aggregation: To create fair measurement, we ranked models on each benchmark individually, then computed average ranks across all tasks and plotted the 95% confidence interval as error bars. Lower average rank = better overall performance.
Training Details
Each model was fine-tuned on synthetic data generated using our distillation pipeline (see Small Expert Agents from 10 Examples for details on the data generation process). For each benchmark, we generated 10,000 training examples using the teacher model (GPTOss-120B).
Fine-tuning was performed using the default distil labs configuration: 4 epochs with learning rate of 5e-5, linear learning rate scheduler and LoRA with rank 64.
All models were trained with identical hyperparameters. Evaluation was performed on held-out test sets that were never seen during training or synthetic data generation.
Conclusion
Not all small models are created equal, but the differences narrow dramatically after fine-tuning. Our benchmarks show that Qwen3-8B delivers the best overall fine-tuned performance, while Qwen3-4B-Instruct-2507 matches a 120B+ teacher on 8 of 9 benchmarks at half the parameter count. For extremely constrained environments, Liquid AI’s LFM2 family stands out: these models absorb training signal more effectively than any other family, making them ideal when you need maximum performance from minimal parameters.
The bottom line: fine-tuning matters more than base model choice. A well-tuned 1B model can outperform a prompted 8B model. If you have a task in mind, start with a short description and a handful of examples - we’ll take it from there.
Want to try this yourself? Sign up for distil labs and train your first expert agent in under 24 hours.